Dataset configureren voor Process Mining
Handleiding voor dataset-upload en het configuratiescherm
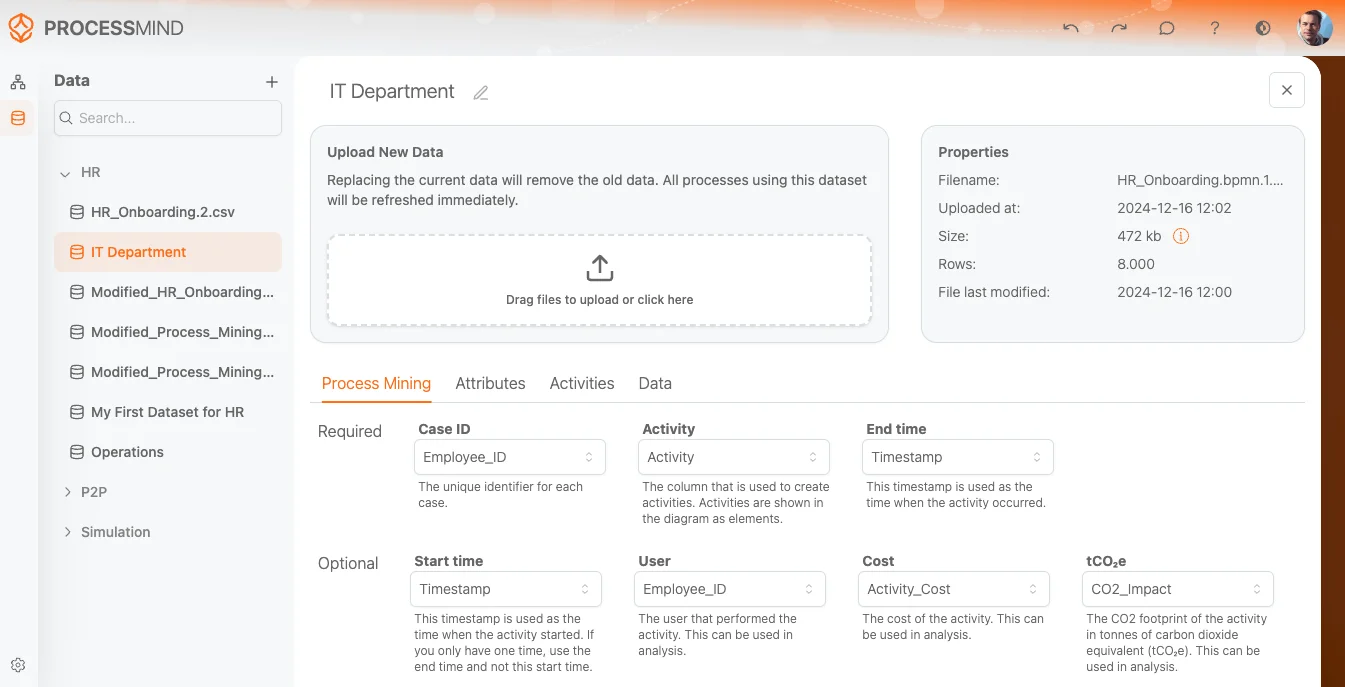
Zodra je dataset volledig is geüpload, zie je het datasetscherm. Hier stel je in hoe je data geïnterpreteerd wordt voor Process Mining analyse. Dit scherm is verdeeld in een aantal hoofdsecties waarmee je het beheer van je dataset, het koppelen van attributen aan datakolommen en het bekijken van bestandsInformatie regelt.
1. Weergavenaam
Koppelingsboven op het scherm vind je het veld Weergavenaam waarmee je:
- De naam van de dataset kunt bewerken: Pas de naam aan naar iets wat duidelijk het type data aangeeft (bijv. “Klant Orders Data” of “Incident Reports”).
2. Upload Dataset
In het midden van het scherm vind je het Upload Dataset gedeelte waar je:
- Een bestand kunt slepen en neerzetten om te uploaden.
- Of je kunt in het vak klikken om een bestand op je computer te selecteren.
- Na upload toont dit deel de details van het geüploade bestand.
3. Bestandseigenschappen
Rechts, onder het Properties paneel, zie je details van het geüploade bestand, zoals:
- Filename: De naam van het bestand (bijv.
P2P event log.csv). - Uploaded at: Datum en tijd van uploaden.
- File size: Grootte van het bestand in MB (bijv.
7,89 MB). Via het (Info) icoon krijg je meer details over het bestandsgebruik in het systeem. - Rows: Aantal rijen in de dataset (bijv.
50.000). - Last modified: Laatste bewerkingsdatum voor upload (bijv.
28 feb 2024).
Deze sectie biedt de belangrijkste Informatie om te checken of het juiste bestand is geüpload.
4. Tabs voor configuratie
Onder de datasetnaam en het uploadgedeelte vind je een tabnavigatie met deze tabs:
- Process Mining (nu actief)
- Attributen
- Activities
- Data
Elke tab geeft opties om een ander deel van je dataset in te stellen. In deze sectie focussen we op de tab Process Mining.
5. Process Mining Tab
De Process Mining tab laat je kolommen uit je dataset koppelen aan de verplichte en optionele velden voor process mining. Hierdoor weet de tool hoe je data geïnterpreteerd moet worden voor analyse.
Verplichte velden
-
Case-ID:
- Dit is het unieke kenmerk voor elke procesinstantie (of “case”) in je dataset.
- Gebruik de dropdown om de correcte kolom voor Case-ID te kiezen (deze is verplicht voor analyse).
-
Activiteit:
- Deze kolom geeft de activiteit of gebeurtenis aan die geanalyseerd wordt (bijv. “Order Created” of “Payment Processed”).
- Selecteer de relevante kolom in je dataset (bijv. “activity_due”) om activiteiten in het proces aan te geven.
-
End Time:
- De timestamp van wanneer de activiteit of gebeurtenis plaatsvond.
- Selecteer de kolom met de eindtijd (bijv. “system_created_on”).
Optionele velden
-
Starttijd:
- Geeft aan wanneer de activiteit is gestart.
- Staat deze Informatie in je dataset, kies dan de juiste kolom via het dropdown-menu.
-
Gebruiker:
- De gebruiker of entiteit die de actie uitvoert (bijv. medewerker, systeem of afdeling).
- Kies de bijbehorende kolom als dit van toepassing is.
-
Kosten:
- De kosten per activiteit of gebeurtenis.
- Worden kosten bijgehouden in je dataset, koppel dan die kolom.
-
CO2:
- De CO2-footprint per activiteit (indien aanwezig).
- Koppel de kolom met deze cijfers om milieubelasting te monitoren.
6. Optionele configuratie in andere tabs
Na het instellen van de verplichte en optionele velden onder de tab Process Mining, kun je ook deze tabs gebruiken voor extra configuratie:
- Attributen: Extra attributen aanpassen of toevoegen.
- Activities: Activiteit-specifieke instellingen voor volledigere workflowanalyse.
- Data: Je data bekijken of opschonen vóór analyse.
Laatste stappen
- Controleer je keuzes om zeker te weten dat de juiste kolommen aan de juiste velden zijn gekoppeld.
- Als alles goed is gemapt, kun je starten met de Process Mining analyse op basis van je ingestelde data.
Als je deze stappen volgt, staat je dataset goed klaar voor analyse en krijg je nuttige inzichten uit je process mining activiteiten in ProcessMind.