このページの内容
データセット設定ガイド
データセットのアップロードと設定画面マニュアル
データセットをアップロードすると、データセット画面が表示されます。この画面でプロセスマイニング分析向けにデータの解釈方法を設定できます。画面はいくつかの重要なセクションに分かれ、データセットの管理やカラムへの属性割り当て、ファイル情報の確認ができます。
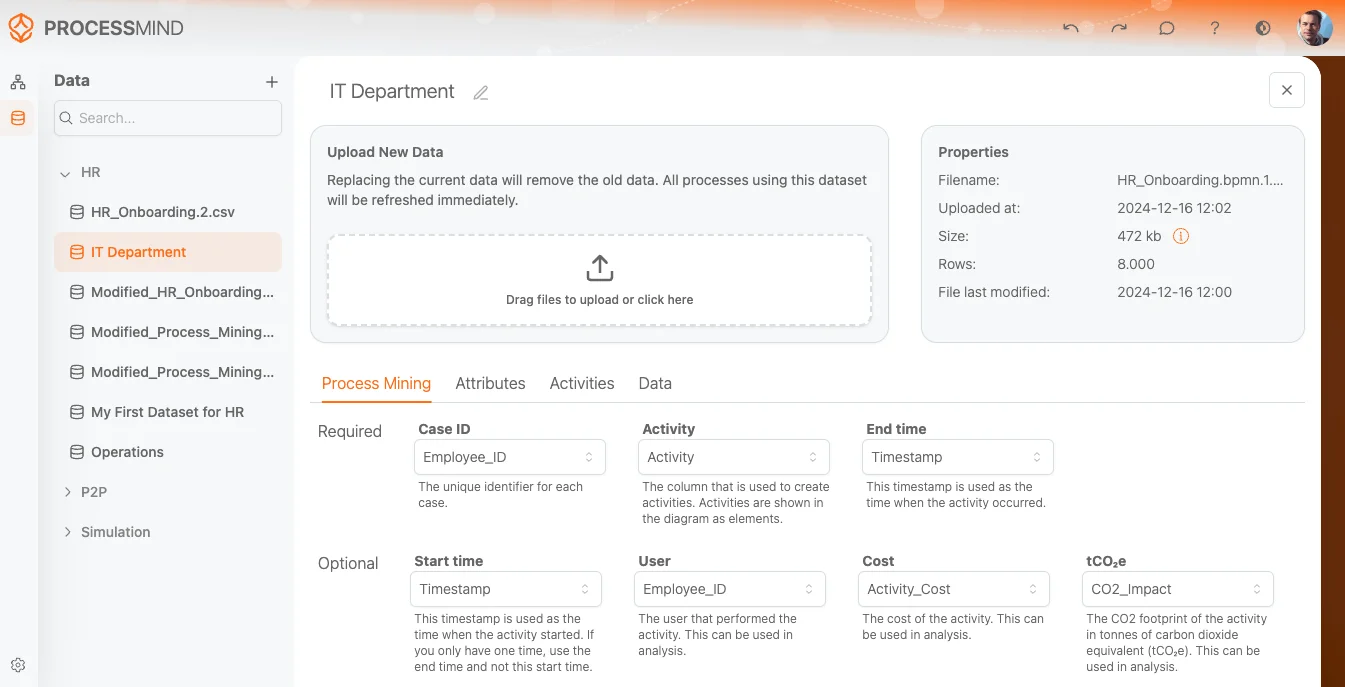
1. 表示名
画面左上の表示名フィールドでは下記が可能です:
- データセット名の編集:内容を分かりやすく表す名前(例:「Customer Orders Data」「Incident Reports」など)へ変更できます。
2. データセットのアップロード
中央にはデータセットアップロードエリアがあります。
- ファイルをドラッグ&ドロップしてアップロード
- またはボックス内をクリックし、PCからファイルを選択
- アップロード後、このエリアにファイルの詳細が表示されます。
3. ファイルプロパティ
右側のプロパティパネルでアップロード済みファイルの詳細を確認できます。
- ファイル名:アップロードしたファイル名(例:
P2P イベントログ.csv) - アップロード日時:ファイルがアップロードされた正確な日時
- ファイルサイズ:ファイルサイズ(例:
7.89MB) - (Info)アイコンでシステムでのファイル利用状況の詳細も確認可能
- 行数:データセットに含まれる行数(例:
50,000行) - 最終更新日:アップロード前にファイルが最後に更新された日(例:
2024年2月28日)
このセクションで正しいファイルがアップロードされているか確認できます。
4. 設定用タブ
データセット名とアップロードエリアの下にタブが並んでいます。
- プロセスマイニング(現在アクティブ)
- Attributes
- Activities
- Data
各タブでデータセットの様々な設定ができます。ここではプロセスマイニングタブについて説明します。
5. プロセスマイニングタブ
プロセスマイニングタブでは、データセットのカラムを必須・任意フィールドにマッピングできます。これによりツールが分析時にデータを適切に解釈できるようになります。
必須フィールド
-
ケースID:
- 各プロセスインスタンス(または「case」)を一意に識別するIDです。
- ドロップダウンでCase IDに該当するカラムを選択してください(分析で必須)。
-
Activity:
- 分析対象となるアクティビティやイベント(例:「Order Created」「Payment Processed」)を示します。
- プロセス内活動を表すカラム(例:「activity_due」)を選択してください。
-
End Time:
- アクティビティやイベント発生時刻のタイムスタンプです。
- 終了時刻に該当するカラム(例:「system_created_on」)を選んでください。
任意フィールド
-
Start Time:
- アクティビティの開始時刻を表します。
- データセットに開始時刻があれば、ドロップダウンから対応するカラムを選択します。
-
User:
- アクティビティ実行者や部門、システムなどです。
- 該当データがあれば、そのカラムを選びます。
-
コスト (Cost):
- 各アクティビティやイベントのコストです。
- コスト情報がある場合は、そのカラムをマッピングしてください。
-
CO2:
- 各アクティビティのCO2排出量(可能な場合)。
- 環境影響を記録したい場合は該当カラムを選択します。
6. その他タブでの追加設定
プロセスマイニングタブで必須・任意フィールドを設定した後は、以下のタブから追加設定が可能です。
- Attributes:属性の追加やカスタマイズ
- Activities:ワークフロー分析のためのアクティビティ設定
- Data:分析前にデータの確認やクリーニング
最終ステップ
- 選択内容を確認し、正しいカラムが適切なフィールドにマッピングされているか確認しましょう。
- マッピング後、設定済みデータでプロセスマイニング分析を進められます。
これらのステップにより、データセットが分析に最適な状態となり、ProcessMindでのプロセスマイニングから有益なインサイトが得られます。