Configurer votre jeu de données de données
Guide d’import et de configuration du dataset
Une fois votre jeu de données de données importé, vous accédez à l’écran Dataset. Ici, vous déterminez comment vos données seront interprétées pour l’analyse Process Mining. L’écran comporte plusieurs sections clés permettant de gérer le dataset, d’assigner des attributs aux colonnes et de consulter les propriétés du fichier.
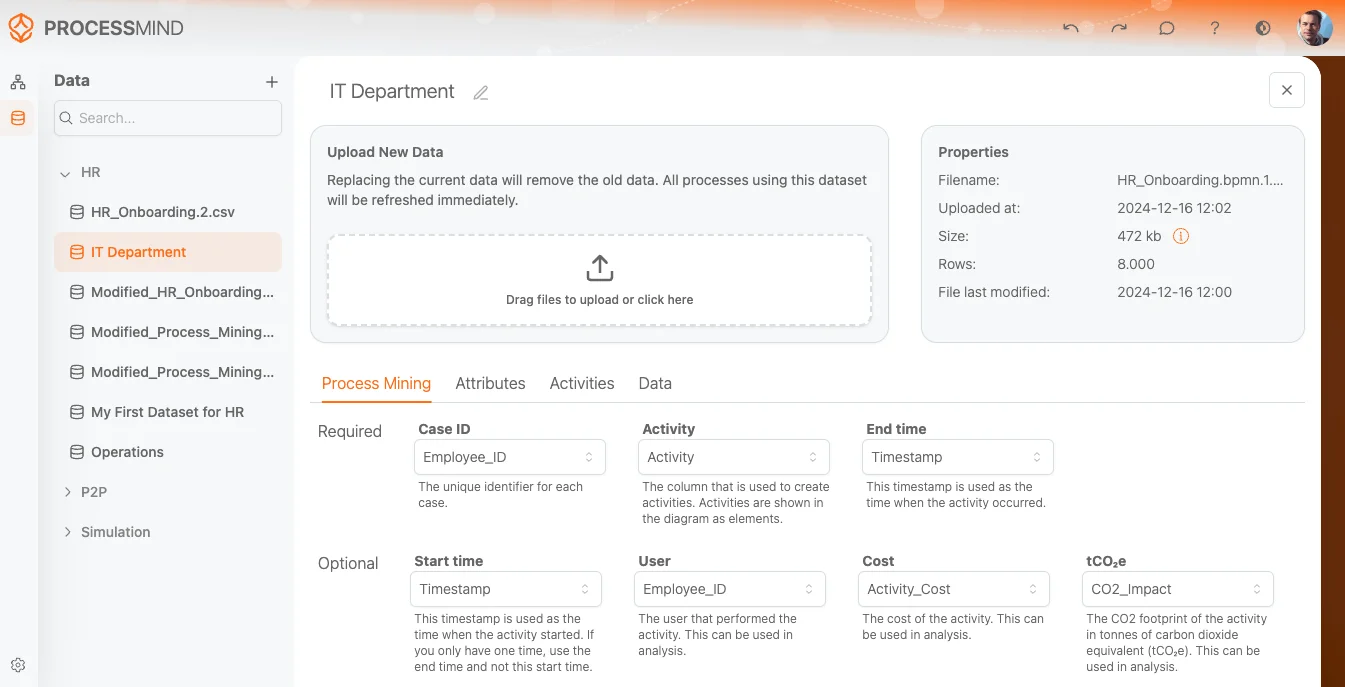
1. Nom d’affichage
En haut à gauche de l’écran, le champ Nom d’affichage permet de :
- Modifier le nom du dataset : Changez le nom pour qu’il reflète le contenu (ex. : « Données commandes clients » ou « Rapports d’incident »).
2. Importer un dataset
Au centre, retrouvez la zone Importer un dataset où vous pouvez :
- Glisser-déposer un fichier à importer.
- Ou cliquer dans la zone pour parcourir et sélectionner un fichier sur votre ordinateur.
- Une fois le fichier importé, ses détails s’affichent ici.
3. Propriétés du fichier
À droite, dans le panneau Properties, consultez les informations sur le fichier importé, notamment :
- Filename : Nom du fichier importé (ex :
P2P journal d'événements.csv). - Importé le : Date et heure précises d’importation.
- Taille du fichier : Taille du fichier en Mo (ex :
7,89 Mo). L’icône (Info) donne plus de détails sur l’utilisation du fichier dans le système. - Lignes : Nombre de lignes ou entrées dans le dataset (ex :
50 000rows). - Dernière modification : Dernière date de modification du fichier avant import (ex :
28 févr. 2024).
Cette section permet de vérifier que le bon fichier a bien été importé.
4. Onglets de configuration
Sous le nom du dataset et la zone d’import, une barre à onglets propose :
- Process Mining (actif)
- Attributes
- Activités (Activities)
- Data
Chaque onglet permet de régler différents aspects du dataset. Nous détaillons ici l’onglet Process Mining.
5. Onglet Process Mining
L’onglet Process Mining sert à associer les colonnes du dataset aux champs requis ou optionnels pour l’analyse. L’outil saura ainsi comment interpréter vos données.
Champs obligatoires
-
ID du cas :
- Identifiant unique pour chaque instance de process (ou “case”) du dataset.
- Sélectionnez la colonne correspondante dans la liste (obligatoire pour l’analyse).
-
Activity :
- Champ indiquant l’activité ou événement analysé (ex : « Order Created », « Payment Processed »).
- Choisissez la colonne du dataset qui indique les activités (ex : « activity_due »).
-
End Time :
- Horodatage indiquant le moment où l’activité ou événement a eu lieu.
- Sélectionnez la colonne correspondant à la fin de l’événement (ex : « system_created_on »).
Champs optionnels
-
Heure de début :
- Indique la date/heure de début de l’activité.
- Si cette info figure dans votre jeu de données de données, choisissez la colonne correspondante.
-
User :
- Utilisateur ou entité ayant réalisé l’activité (ex : employé, système, département).
- Si disponible, sélectionnez la colonne concernée.
-
Cost :
- Coût lié à chaque activité ou événement.
- Si votre jeu de données de données contient un suivi des coûts, associez la colonne adéquate.
-
CO2 :
- Empreinte CO2 de chaque activité (si disponible).
- Sélectionnez la colonne correspondante pour suivre l’impact environnemental.
6. Configurations optionnelles dans les autres onglets
Après avoir renseigné les champs nécessaires dans l’onglet Process Mining, explorez les onglets suivants pour des réglages complémentaires :
- Attributes : Personnalisez et attribuez des attributs à votre jeu de données de données.
- Activités (Activities) : Configurez les paramètres relatifs aux activités pour affiner l’analyse des workflows.
- Data : Affichez ou nettoyez vos données avant analyse.
Étapes finales
- Vérifiez vos sélections pour garantir que les bonnes colonnes sont associées aux champs appropriés.
- Une fois tout correctement configuré, vous pouvez lancer l’analyse Process Mining sur les données sélectionnées.
En suivant ces étapes, votre jeu de données de données sera prêt pour l’analyse et vous obtiendrez des informations essentielles issus de vos activités de process mining avec ProcessMind.