Master Data-mapping voor Procesoptimalisatie
Haal alles uit data mapping in ProcessMind. Leer hoe je processen verbindt, visualiseert en optimaliseert voor betere bedrijfsresultaten.
Het mappen van datasets is belangrijk om ruwe data om te zetten in concrete inzichten in ProcessMind. Een belangrijk voordeel van ProcessMind is de flexibiliteit: je kunt altijd data toevoegen, verwijderen, activeren of deactiveren wanneer dat nodig is. Je hoeft geen vaste volgorde aan te houden voor het integreren van data in je proces.
Er zijn twee belangrijke manieren om met data te werken:
Dankzij deze flexibiliteit kies je zelf de werkwijze die het beste aansluit bij jouw situatie.
Voor deze documentatie gaan we ervan uit dat je begint met een leeg canvas en stap voor stap je proces en analyse opbouwt. Wil je liever beginnen met een bestaand proces, dan kun je een bestaand BPMN-model importeren en direct data koppelen aan taken en gebeurtenissen van het geïmporteerde model .
Begin met een nieuw proces of open een bestaand proces. De canvas vormt de basis voor je model, waar je datasets mappt en structureert. Heb je in de data-sectie nog geen data geüpload? Je kunt ook direct data uploaden vanuit de procesweergave. Ga hiervoor naar het rechter paneel en kies de dataset in het modal, zoals weergegeven op de afbeelding hieronder.
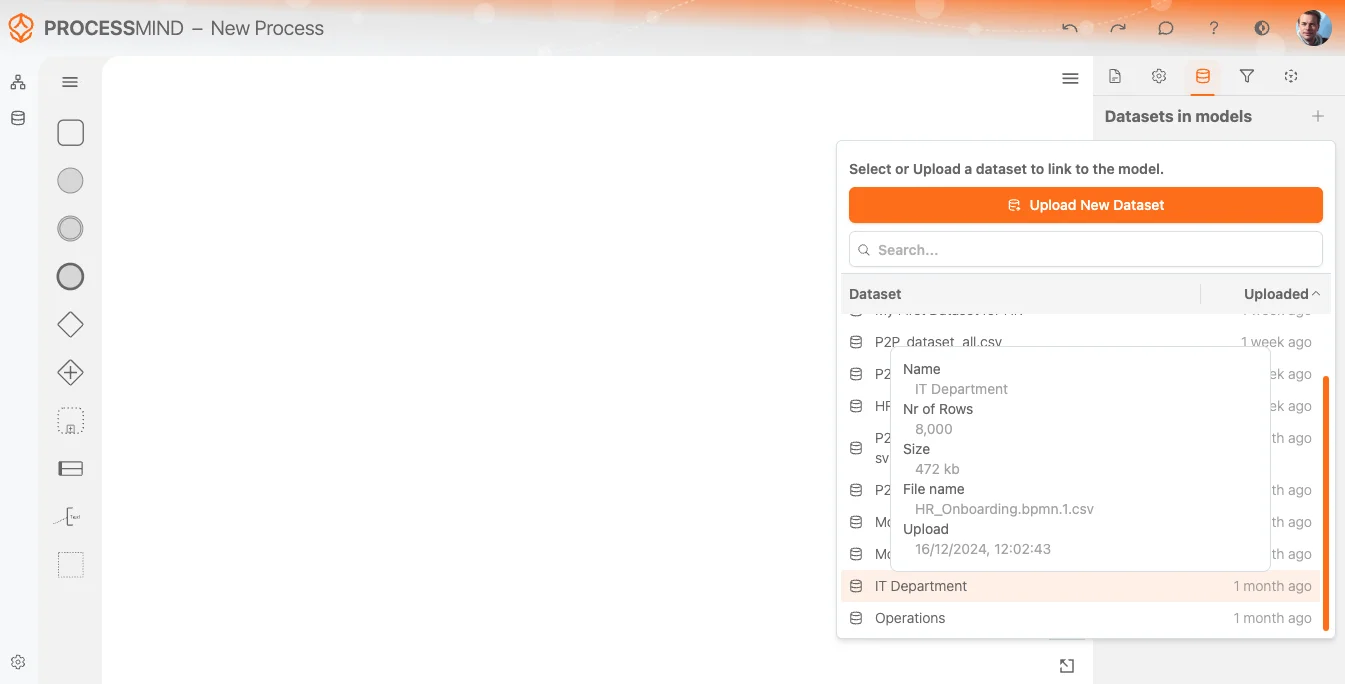
Na uploaden en processen van je dataset geeft het systeem aan dat deze klaar is voor gebruik. Je selecteert de dataset via de datasetlijst zoals te zien op de afbeelding hierboven. De meest recent geüploade dataset staat altijd bovenaan voor snelle toegang.
Beweeg met je muis over een dataset voor extra Informatie via een toolTip, bijvoorbeeld:
Zo weet je zeker dat je de juiste dataset voor je proces kiest.
Na selectie voert het systeem basis-preprocessing uit. Dit zie je aan het laadicoon naast de datasetnaam.
Voor dit proces kun je de naam van de dataset aanpassen indien gewenst; zo blijft het later makkelijk herkenbaar. Met de switch kun je instellen of de dataset geactiveerd of gedeactiveerd is voor processen.
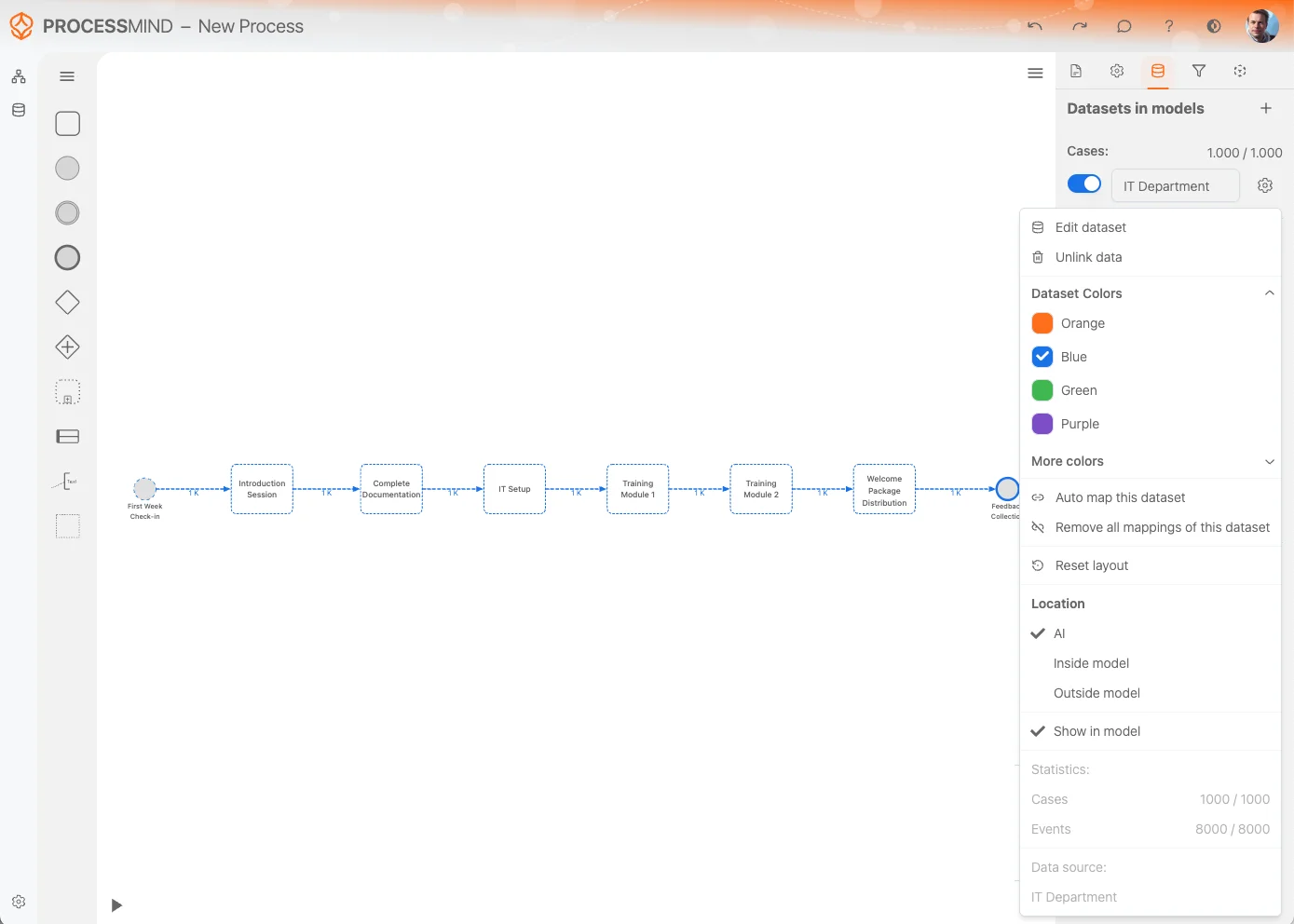
Het Dataset instellingenmenu biedt meerdere opties om je dataset effectief te beheren en aan te passen. Hieronder vind je een overzicht van de beschikbare opties:
Bewerken Dataset:
Open direct de Bewerken Dataset optie om de dataset zelf te wijzigen of aan te vullen.
Data ontkoppelen:
Heb je de dataset niet meer nodig in het proces? Gebruik Data ontkoppelen om alle verwijzingen uit je procescanvas te verwijderen.
Let op: Hiermee verwijder je de dataset niet definitief, deze blijft beschikbaar in de datasetlijst.
Datasetkleuren:
Pas de kleur van de dataset aan voor een duidelijk visueel onderscheid. Deze kleur geldt ook voor activiteiten afkomstig uit deze dataset en helpt bij herkenning op de canvas.
Dataset automatisch in kaart te brengen:
Probeer automatisch de activiteiten van de dataset te mappen op bestaande activiteiten in het procesmodel. Dit bespaart tijd en verhoogt de consistentie.
Alle koppelingen verwijderen:
Maak alle koppelingen tussen activiteiten van de dataset en je procesmodel in één keer leeg. Handig als je opnieuw wilt beginnen of grote wijzigingen wil doorvoeren.
Lay-out herstellen:
Met Lay-out herstellen worden activiteiten en hun onderlinge relaties automatisch netjes gerangschikt op de canvas voor overzicht en helderheid.
Locatie:
Bepaal waar het automatisch gegenereerde model wordt getoond:
In model tonen:
Hiermee kun je activiteiten uit de dataset die (nog) niet direct gemapt zijn verbergen of tonen. Zo houd je controle over de zichtbaarheid van niet-gemapte activiteiten.
Statistieken:
Bekijk statistieken van de dataset, zoals:
Met deze opties beheer je integratie, presentatie en gedrag van datasets binnen je procesmodellen voor een soepel en gestructureerd workflowbeheer.
Als de dataset volledig is geladen, toont het systeem automatisch het Process Mining resultaat op de canvas. Deze eerste procesmap is een zwevend model zonder vaste koppelingen. Om het onderdeel te maken van je procesontwerp en aanpasbaar te maken, moet je deze mappen op een bestaand model of activiteit, of omzetten naar een vast model.
Er zijn twee manieren om activiteiten vanuit het zwevende model op de canvas vast te zetten:
Activiteiten individueel selecteren:
Kies specifieke activiteiten om ze één voor één te mappen.
Meerdere activiteiten tegelijk selecteren:
Gebruik de selectietool of sneltoetsen om meerdere activiteiten tegelijk te selecteren:
Ctrl + A (Windows) of Command + A (MacOS) voor alles selecteren.Na selectie verschijnt er een nieuw contextmenu naast de activiteiten. Hier kun je kiezen voor Add to Model: Hiermee zet je de geselecteerde activiteiten vast op de canvas zodat je:
Door joje datasetprocesmap vast te zetten op de canvas kun je je proces verrijken met meer details, relaties en context en maak je van ruwe data direct concrete inzichten.
Unmapt activiteiten zijn activiteiten die in de dataset staan, maar nog niet aan attributen in het model zijn gekoppeld. Dit geeft mogelijke hiaten of onderdelen aan die nog in je procesontwerp moeten worden opgenomen.
Als je de optie Unmapt Activities aan- of uitzet, worden de unmapt data zichtbaar als sTippellijnen. Zo zie je snel welke activiteiten nog niet gemapt zijn.
In het voorbeeld zie je de situatie voor en na het inschakelen van unmapt activiteiten:
Met deze functie beheer je unmapt data makkelijk en zorg je dat je procesmodel compleet en accuraat is.
Door datasets te mappen in ProcessMind maak je van data een krachtig hulpmiddel voor procesanalyse. Of je nu start met een bestaand proces of ruwe data, dankzij de flexibiliteit van het platform kun je je model eenvoudig opbouwen en aanpassen. Door deze stappen te volgen, bouw je een compleet model waarmee je direct concrete inzichten krijgt om processen te verbeteren.
We gebruiken cookies om je ervaring te verbeteren, gepersonaliseerde inhoud te tonen en het verkeer op onze site te analyseren. Door op "Alles accepteren" te klikken, ga je akkoord met ons gebruik van cookies.