データセットのマッピング方法
ProcessMindにおけるデータセットのマッピング
ProcessMindでデータセットをマッピングすることは、生データを実用的なインサイトに変換する重要なステップです。ProcessMindの大きな特長は、データの追加・削除・有効化・無効化をいつでも柔軟にできる点です。データ統合の順序や決まったやり方の制約はありません。
データ利用には主に2つのアプローチがあります:
- プロセス定義後にデータ追加:先にプロセスの枠組みを作ってから、データを組み込み、抜けや改善点を特定して分析を深めます。
- データからスタート:eventデータを初期プロセスマップとして取り込み、そこからモデル化を進めます。
この柔軟性により、状況に合わせてベストな方法を選べます。
このドキュメントでは、空のキャンバスからプロセスや分析を一歩ずつ構築していくことを前提としています。既存のプロセスから始めたい場合は、既存のBPMNモデルをインポート し、インポートしたモデルのTaskやEventにデータを直接マッピング することもできます。
ステップ 1: 空のキャンバスからはじめる
最初に新規プロセス作成または既存のプロセスを開きます。キャンバスはモデルの土台になり、ここでデータセットをマッピング・整理します。 データセクションで未アップロードの場合も、プロセスビューの右パネルから「モーダル」セクション経由で直接データを追加できます。
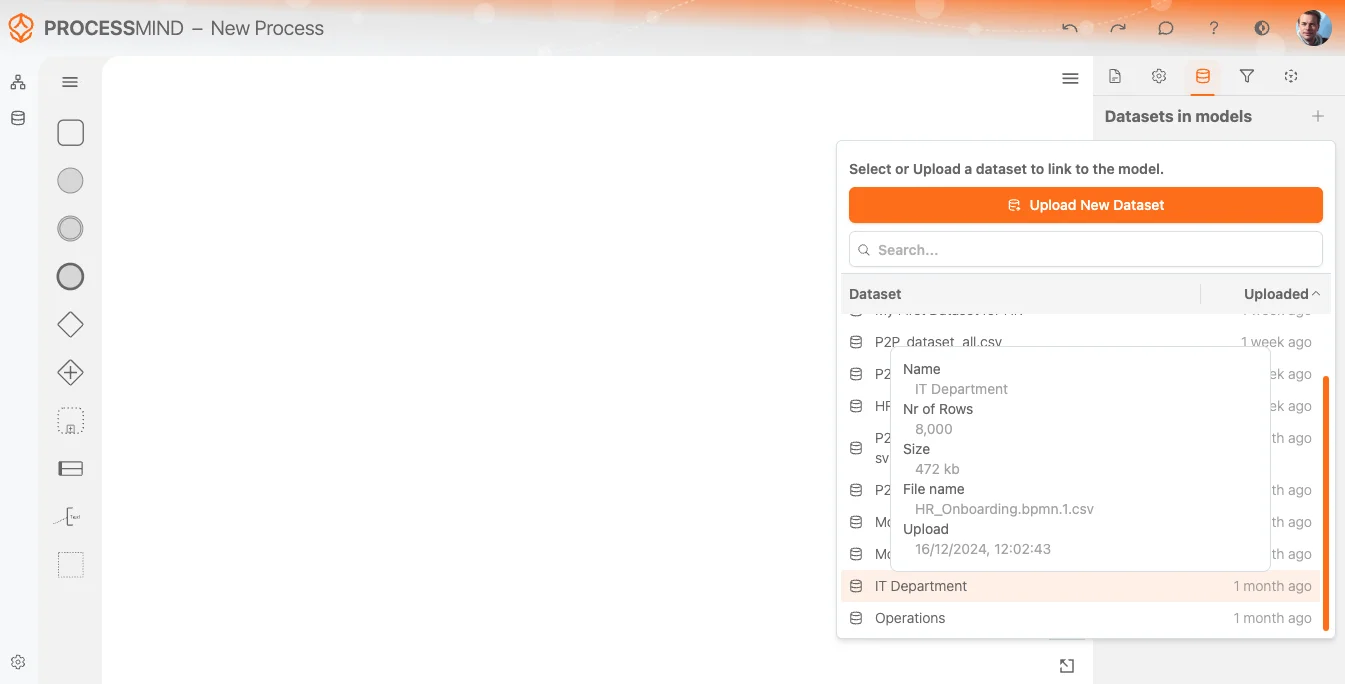
データセットを選択
データセットをアップロードし処理が完了すると、システムより利用可能の通知が届きます。データセットリストから選択でき、直近アップロード分は常に一番上に並びます。
データセットにカーソルを合わせると、次のような追加情報がツールチップで表示されます:
- データセット名
- 行数
- ファイルサイズ・ファイル名
- アップロード日時
これにより、正しいデータセットを確実に選べます。
選択後はシステムによる事前処理が行われ、データセット名横にローディングアイコンが表示されます。
プロセス内での分かりやすさ重視で、その用途にあわせてrenameも可能です。スイッチでプロセスごとの有効/無効切り替えも行えます。
データセットオプション
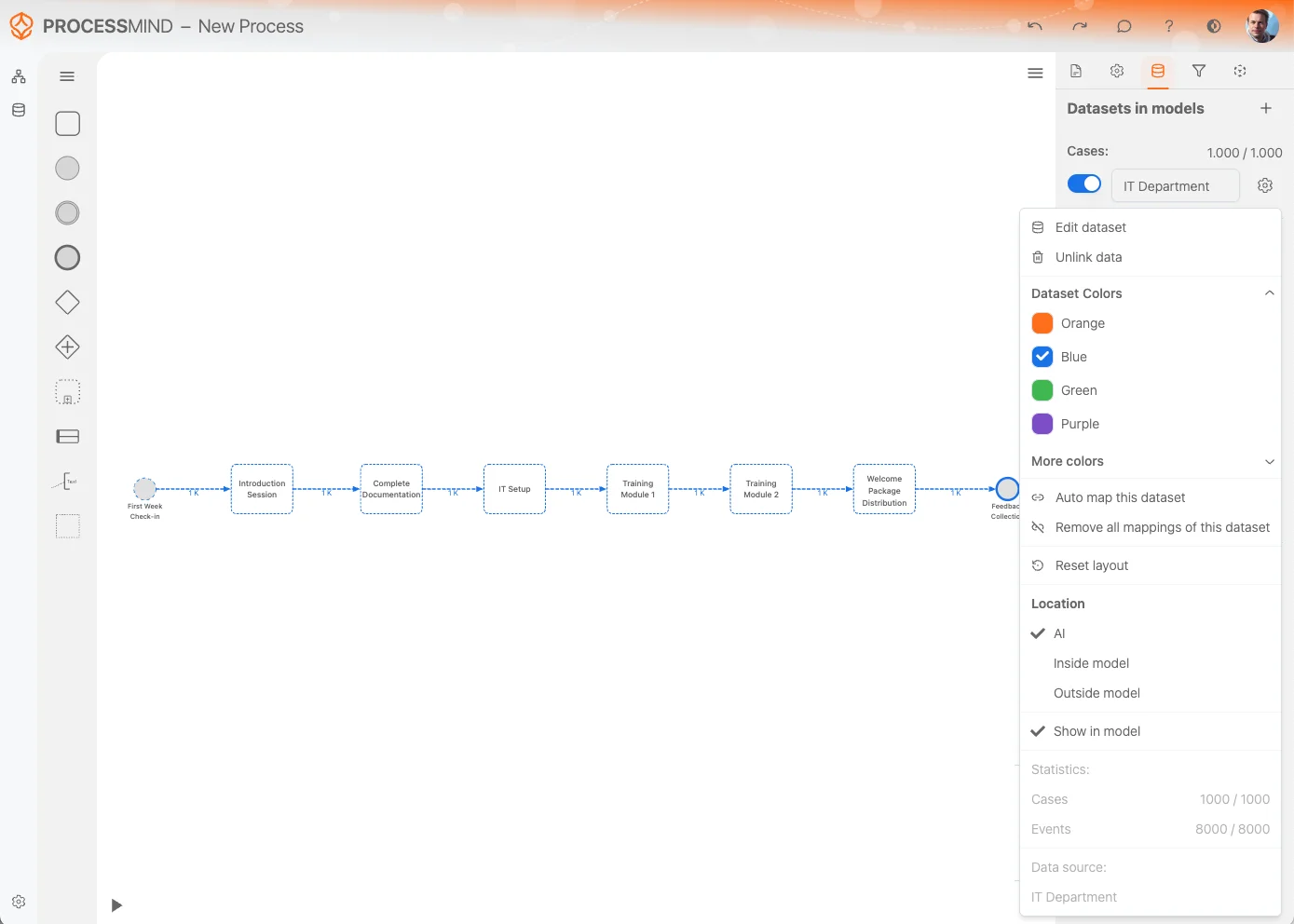
Dataset 設定メニュー では、データセットの管理やカスタマイズを効率良く行うための様々なオプションが選べます。主な機能は下記の通りです:
-
Edit Dataset:
Edit Dataset オプションですぐにデータセットの内容を編集・修正できます。データセット自体を直接変更できます。 -
Unlink Data:
プロセスでデータセットが不要な場合、Unlink Data を選択すると、プロセスキャンバスから該当データセットの参照が全て削除されます。
注記: この操作ではデータセット自体は消去されず、データセットリスト に残ります。 -
Dataset Colors:
データセットの色を変更して視覚的に区別しやすくできます。選択した色はそのデータセット由来のアクティビティにも反映され、キャンバス内で識別しやすくなります。 -
Auto Map Dataset:
データセット内のアクティビティをモデル上の既存アクティビティに自動マッピングします。時間短縮と一貫性維持に役立ちます。 -
Remove All Mappings:
データセットとプロセスモデル間の全てのアクティビティマッピングをリセットします。やり直したい時や大きな変更が必要な時に便利です。 -
Reset Layout:
Reset Layout オプションで、キャンバス上のアクティビティとその関係が自動で整理され、見やすくなります。 -
Location:
自動生成モデルの表示場所を決めます。- AI (Smart Detection): AIが最適な場所を自動判断します。
- Inside Model: プロセスキャンバス内にモデルを配置。
- Outside Model: プロセス設計外にモデルを表示し分離性を高めます。
-
Show in Model:
モデル上でマッピングされていないアクティビティの表示・非表示を切り替えて管理できます。未マップアクティビティの可視性をコントロールできます。 -
Statistics:
データセットの統計を確認できます:- Number of Cases and Events: データセットの規模を簡単に把握できます。
- Original Data Source Name: 参照しやすいようにデータセット元の名称を表示します。
これらのオプションを使うことで、プロセスモデル内でのデータセット管理、可視化、運用を効率化し、シームレス・整理されたワークフローを実現します。
データをプロセスへマッピング
データセットの読み込みが完了すると、システムはプロセスマイニング結果を自動でキャンバスに表示します。この最初のプロセスマップは、まだどの要素にも固定されていないフローティングモデルです。これをプロセス設計の一部として編集可能にするには、既存モデルやアクティビティへマッピングするか、固定モデルへ変換する必要があります。
モデルをキャンバスへ固定する
フローティングモデル内のアクティビティをキャンバスに固定する主な方法は2つあります:
-
個別選択: 特定アクティビティを個別に選択してマッピング
-
まとめて選択: 選択ツールやショートカットで複数アクティビティを一括選択
- Shift+ドラッグ: 対象を囲み複数選択
- 全選択:
Ctrl + A(Windows)やCommand + A(Mac)で全アクティビティ選択
選択するとコンテキストメニューが出ます。ここで「Add to Model」を選ぶと、選択内容がキャンバスへ固定されます。
- アクティビティへコンテキスト追加
- 他属性との関連付けや、追加属性のマッピング/解除も可能
データセットのプロセスマップをキャンバスに固定することで、詳細な属性・関係性・コンテキストを加え、本当の意味で業務データが活用できるようになります。
Unmapped Activities
未マッピングのアクティビティ(Unmapped activities)とは、データセット内に存在していても、まだモデル内の属性にマッピングされていないアクティビティです。これはプロセス設計上、今後統合が必要な部分やギャップを示します。
Unmapped Activities オプションをオン・オフ切り替えると、未マッピングデータは点線で表示されます。この見た目でマッピング済みとの区別が簡単です。
下記のビジュアル例で、未マッピングアクティビティ表示オプションの切替前・切替後の状態を確認できます:
- Before: 未マッピングアクティビティは非表示で、キャンバスに現れません。
- After: 未マッピングアクティビティが点線で表示され、マッピング候補が分かりやすくなります。
この機能を使うことで、未マッピングデータを効率良く管理・対応でき、プロセスモデルの網羅性と正確性を高められます。
まとめ
ProcessMindでデータセットをマッピングすると、データをプロセス分析の強力なツールに変えられます。あらかじめプロセスを定義して始めても、生データから始めてもOK。プラットフォームの柔軟性で、必要に応じてモデルを構築・修正できます。これらの手順を踏めば、有益なビジネスインサイトを得られる最適なプロセスモデルを作成し、継続的なプロセス改善を実現できます。