数据集 Mapping 操作指南
在 ProcessMind 中进行数据集 Mapping
数据集 mapping 是 ProcessMind 实现原始 data 到可用洞察的核心步骤之一。ProcessMind 一大优势是灵活性:你随时可添加、移除、启用或停用数据,无固定顺序,集成方式自由。
主要有两种处理 data 的方式:
- 先定义流程再加数据: 先搭建流程框架,再导入数据完善分析、识别信息缺口。
- 以数据为起点: 用 event data 创建初始流程 MAP,并逐步完善。
这种灵活设计,让你能按需选择最适合自身需求的 mapping 方法。
本说明文档假设您从空白画布开始,逐步搭建流程并进行分析。如果您更希望基于已有流程,也可直接导入已有 BPMN 模型 ,并将 data 直接映射到已导入模型的 Task 和 Event 。
步骤 1:从空白画布开始
新建流程或打开现有流程,画布即为你 mapping 和组织数据集的基础。 如未在数据区提前上传 data,也可在流程视图直接上传。可从右侧面板进入“数据集”弹窗,如下图所示。
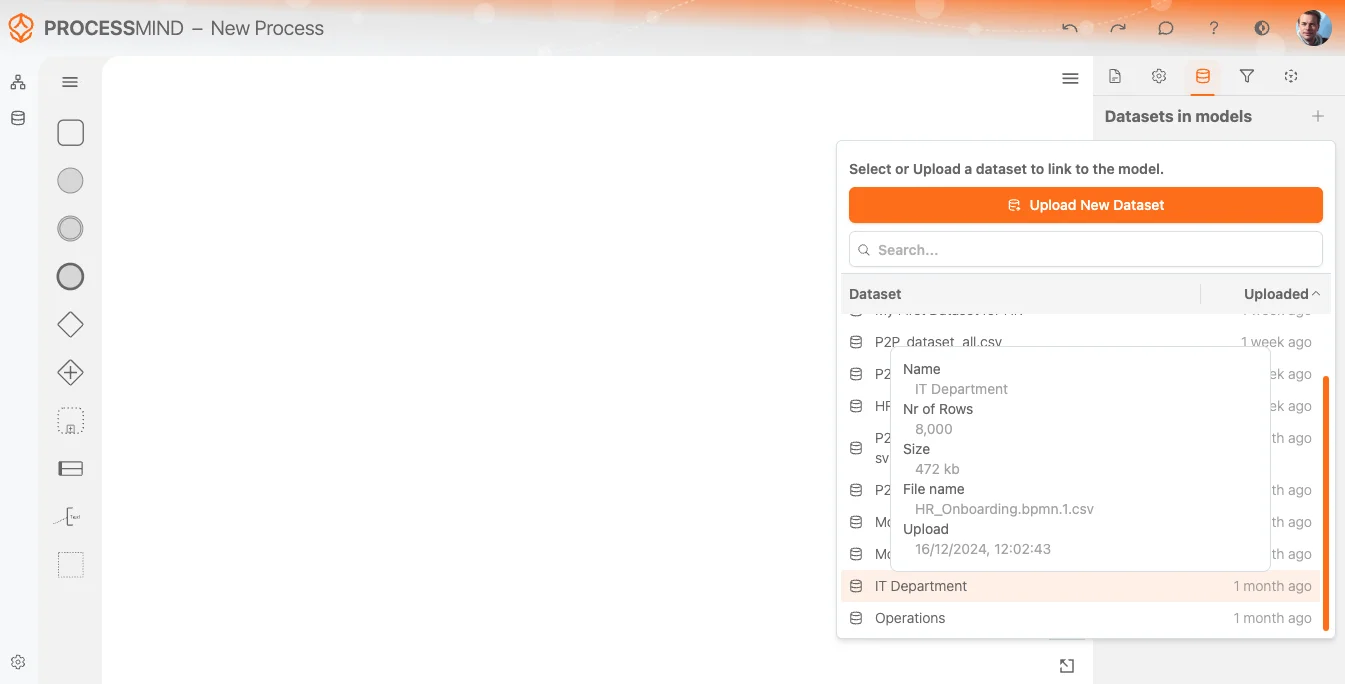
选择你的数据集
上传处理完成后,系统会提醒你数据集可用。你可在数据集列表中选择,最新上传始终排列最上,便于快速访问。
鼠标悬停在数据集上,气泡会显示更多信息,包括:
- 数据集名称
- 识别到的行数
- 上传文件大小和名称
- 上传日期与时间
帮助你确认选中的数据集是否合适。
选择后,系统会自动进行基础预处理,数据集名称旁会显示 loading 图标。
你还可按流程需求重命名数据集,便于区分管理。开关按钮可灵活启用或停用数据集,适应不同流程。
数据集选项
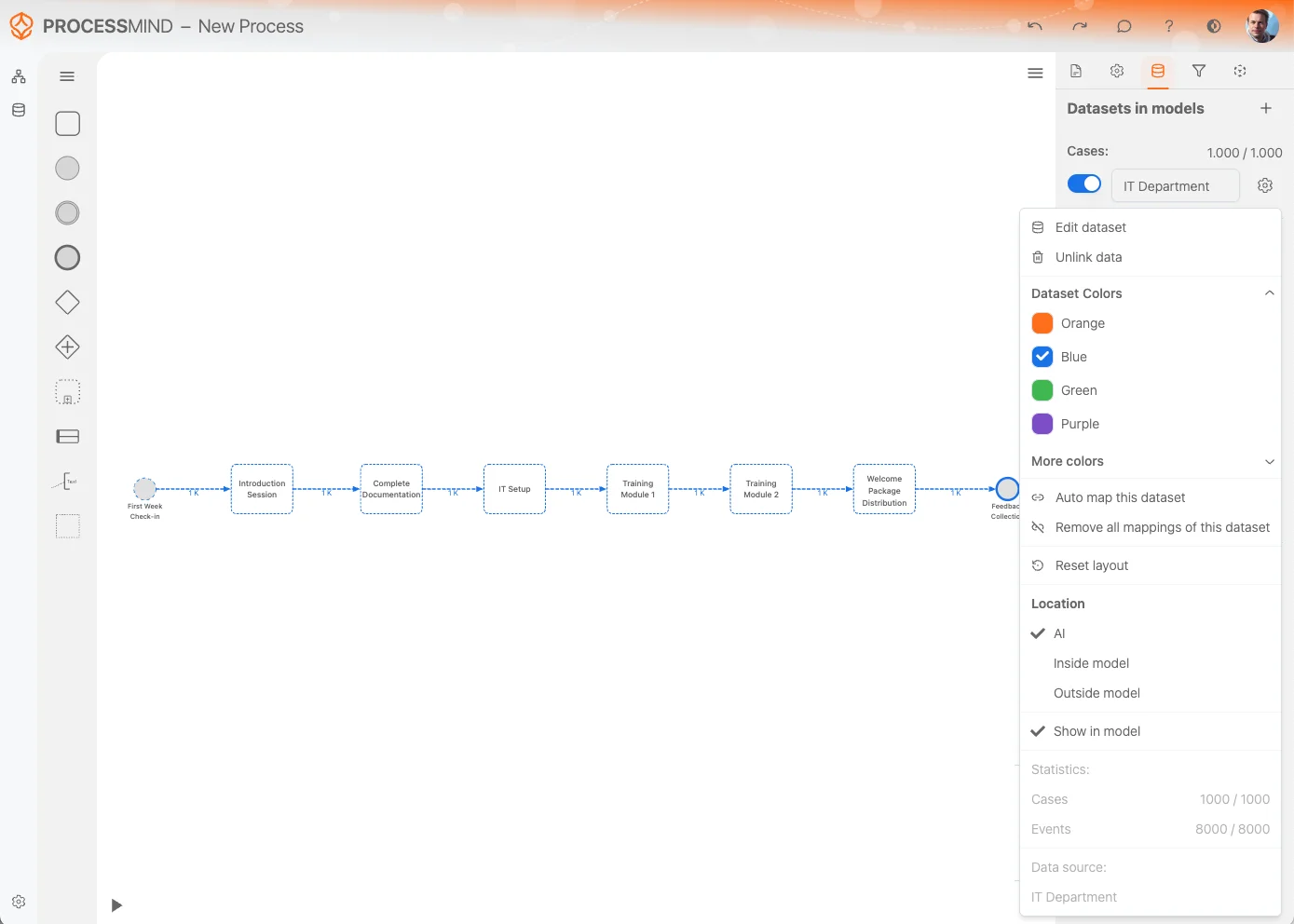
数据集设置菜单 提供多种选项,帮助您高效管理和自定义数据集。以下是各功能简介:
-
编辑数据集:
快速进入 编辑数据集,直接修改或优化数据集内容。 -
解除数据关联:
如果流程不再需要此数据集,可使用 解除数据关联,移除与该数据集的所有引用并从流程画布清除。
注意: 此操作不会删除数据集本身,数据集依然保存在列表中。 -
数据集颜色:
更改数据集颜色以便区分。所选颜色也会应用于所有来源于该数据集的活动,方便画布快速辨识。 -
自动 MAP 数据集:
自动尝试将数据集内的活动映射到流程模型中的现有活动,提升建模效率并保持一致性。 -
移除所有映射:
此选项可清除数据集与流程模型间的所有活动映射,适合重建或大幅调整流程时使用。 -
重置布局:
重置布局 自动整理画布上的活动和关系,让展示更清晰明了。 -
展示位置:
设置自动生成模型的显示区域。- AI(智能检测): 自动选择最佳放置位置。
- 模型内: 在流程画布内部展示模型。
- 模型外: 在流程设计之外展示模型,更易分隔管理。
-
模型中显示:
可控制数据集中未映射到模型的活动是否隐藏。切换此项,灵活管理未映射活动的可见性。 -
统计信息:
查看数据集统计详情,包括:- 案例数 & event 数: 快速了解数据集规模。
- 原始数据源名称: 显示数据来源,便于参考。
通过使用这些选项,您可以高效地管理数据集在流程模型中的集成、展示和行为方式,从而确保 workflow 顺畅且井然有序。
将数据映射到流程
数据集加载完成后,系统将自动在画布上显示 Process Mining 结果。最初的流程图是一个悬浮模型,尚未固定。为了使其成为流程设计的一部分并可供编辑,您需要将其映射到现有的模型或活动,或者将其转换为固定模型。
将模型固定到画布
将活动从悬浮模型固定到画布主要有两种方式:
-
逐个选择活动:
选择特定的活动进行单独映射。 -
批量选择:
使用选择工具或键盘快捷键同时选择多个活动:- Shift + 鼠标拖动: 框选活动。
- 全选: 按
Ctrl + A(Windows) 或Command + A(MacOS) 选中所有活动。
完成选择后,所选活动旁边会出现一个新的上下文菜单。您可以从中执行以下操作:添加到模型: 此选项会将所选活动固定到画布上,以便您:
- 为活动添加上下文信息。
- 将活动与其他属性关联。
- 根据需要映射或取消映射其他属性。
通过将数据集的流程图固定到画布上,您可以开始通过详细的属性、关系和上下文来丰富流程,从而将原始数据转化为可落地的见解。
未映射活动
未映射活动是指数据集中存在但尚未映射到模型中任何属性的活动。它们代表了可能存在的缺口或需要进一步集成到流程设计中的元素。
当您开启或关闭 未映射活动 选项时,未映射的数据将以 虚线 形式呈现。这让您可以轻松识别这些活动并将其与已映射的活动区分开来。
在示例图中,您可以观察开启或关闭“未映射活动”选项的前后状态对比:
- 之前: 未映射活动会被隐藏,在画布上不可见。
- 之后: 未映射活动以虚线显示,突出显示了待映射的区域。
使用此功能,您可以高效地管理和处理未映射的数据,确保流程模型尽可能完整准确。
总结
在 ProcessMind 中映射数据集可将您的数据转化为流程分析的利器。无论您是从既定流程还是原始数据开始,平台的灵活性都能确保您按需构建和完善模型。按照这些步骤操作,您就能满怀信心地创建完整模型,揭示可落地的见解并推动流程改进。