Mapeamento de datasets
Mapeando datasets no ProcessMind
Mapear datasets é essencial para transformar dados brutos em insights de valor dentro do ProcessMind. Um dos grandes diferenciais do ProcessMind é a flexibilidade: você pode adicionar, remover, ativar ou desativar dados a qualquer momento. Não existe uma ordem obrigatória para integrar dados ao seu processo.
Você pode trabalhar com dados de duas formas principais:
- Adicionar dados após definir o processo: Comece estruturando o processo e inclua dados para identificar informações faltantes e refinar sua análise.
- Começar pelos dados: Use seu event data para criar um mapa inicial do processo e evolua a partir disso.
Essa flexibilidade permite que você siga o caminho que fizer mais sentido para sua operação.
Para fins desta documentação, vamos assumir que você está começando com uma tela em branco e construindo seu processo e análise passo a passo. Se preferir começar com um processo já existente, você pode importar um modelo BPMN existente e mapear dados para tasks e events do modelo importado diretamente.
Passo 1: Começando com o Canvas Vazio
Comece criando um novo processo ou abrindo um já existente. O canvas é a base do seu modelo, onde você irá mapear e organizar os datasets.
Se ainda não fez upload dos seus dados na seção de data, é possível enviar os dados diretamente da visão do processo. Basta acessar o painel à direita e ir até a seção de datasets no modal, como mostrado na imagem abaixo.
Selecione seu dataset
Quando o upload do seu dataset for concluído e processado, o sistema notificará que ele está pronto para uso. Você poderá selecioná-lo na Lista de Datasets, como mostra a imagem acima. O dataset enviado mais recentemente sempre aparecerá no topo para facilitar o acesso.
Ao passar o mouse sobre um dataset na lista, um balão de informações (tooltip) fornecerá contexto adicional, como:
- Nome do dataset
- Número de linhas identificadas
- Tamanho e nome do arquivo enviado
- Data e hora do upload
Isso ajuda a garantir que você está selecionando o dataset correto para o seu processo.
Depois de selecionar seu dataset, o sistema fará um pré-processamento básico. Isso será indicado por um ícone de carregamento ao lado do nome do dataset.
Para dar contexto ao seu processo, você pode renomear o dataset (se desejar) especificamente para o uso atual, facilitando a identificação posterior. O seletor dará a opção de ativar ou desativar o dataset para os processos.
Opções do Dataset
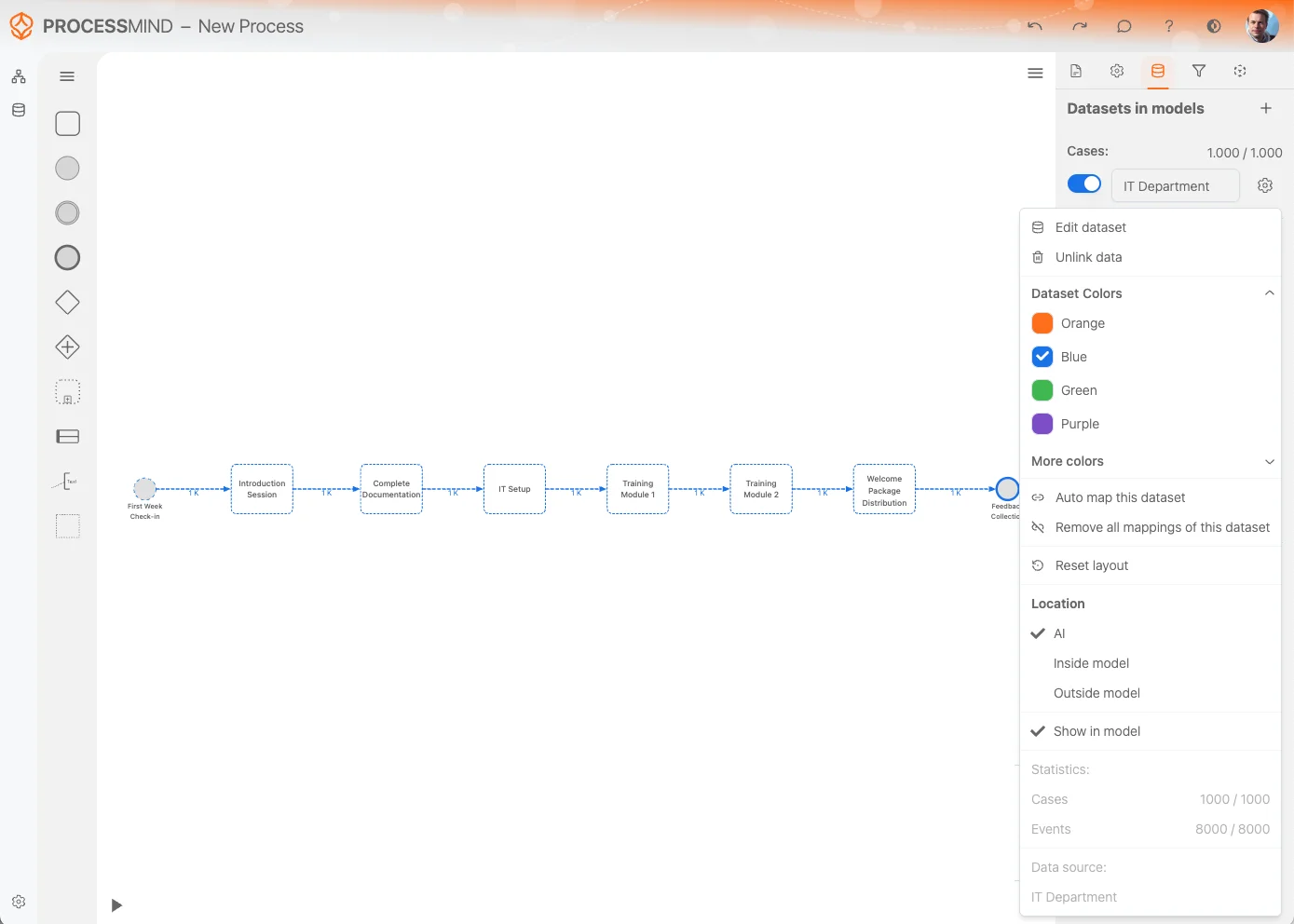
O Menu de Configurações do Dataset oferece várias opções para gerenciar e personalizar seus dados de forma eficaz. Abaixo está uma descrição das opções disponíveis:
-
Editar Dataset:
Acesse rapidamente a opção Editar Dataset para fazer alterações no conjunto de dados. Isso permite modificar ou refinar o dataset diretamente. -
Desvincular dados:
Se você não precisar mais do dataset em seu processo, use a opção Desvincular dados. Isso remove todas as referências ao conjunto de dados e o limpa da tela do seu processo.
Observação: Esta ação não exclui o dataset em si; ele continua disponível na Lista de Datasets. -
Cores do dataset:
Altere a cor do dataset para uma melhor distinção visual. A cor selecionada também será aplicada às atividades derivadas desse dataset, facilitando a identificação na tela. -
Mapeamento automático do dataset:
Esta opção tenta mapear automaticamente as atividades do dataset para as atividades já existentes em seu modelo de processo. Isso economiza tempo e ajuda a manter a consistência. -
Remover todos os mapeamentos:
Use esta opção para limpar todos os mapeamentos de atividades entre o dataset e seu modelo de processo. É útil se você precisar recomeçar ou fazer mudanças significativas. -
Redefinir layout:
A opção Redefinir layout organiza automaticamente as atividades e seus relacionamentos na tela para melhorar a visualização e clareza. -
Localização:
Determine onde o modelo gerado automaticamente será exibido.- IA (Detecção inteligente): Decide automaticamente o local ideal.
- Dentro do modelo: Coloca o modelo dentro da tela do processo.
- Fora do modelo: Exibe o modelo fora do design do processo para melhor separação.
-
Mostrar no modelo:
Esta opção permite ocultar atividades encontradas no dataset que não estão mapeadas diretamente no modelo. Use esta alternância para gerenciar a visibilidade de atividades não mapeadas. -
Estatísticas:
Veja detalhes estatísticos sobre o dataset, incluindo:- Número de casos e eventos: Fornece um resumo rápido do tamanho do dataset.
- Nome da fonte de dados original: Exibe a origem do dataset para facilitar a referência.
Ao utilizar essas opções, você consegue gerenciar com eficiência a integração, a visualização e o comportamento dos datasets em seus modelos de processo, garantindo um fluxo de trabalho fluido e organizado.
Mapeando dados para o processo
Assim que o dataset for totalmente carregado, o sistema exibirá automaticamente o resultado do Process Mining na tela. Esse mapa de processo inicial é um modelo flutuante, sem vínculos fixos. Para torná-lo parte do design do seu processo e editável, você precisa mapeá-lo em um modelo ou atividade existente, ou convertê-lo em um modelo fixo.
Fixando o modelo na tela
Existem duas formas principais de fixar atividades do modelo flutuante na tela:
-
Selecionar atividades individualmente:
Escolha atividades específicas para mapear uma a uma. -
Seleção em massa:
Use a ferramenta de seleção ou atalhos do teclado para escolher várias atividades de uma vez:- Shift + Arrastar o mouse: Desenhe uma caixa de seleção ao redor das atividades.
- Selecionar tudo: Pressione
Ctrl + A(Windows) ouCommand + A(MacOS) para selecionar todas as atividades.
Após fazer a seleção, um novo menu de contexto aparecerá ao lado das atividades selecionadas. Nele, você pode escolher a seguinte ação: Adicionar ao modelo: Esta opção fixa as atividades selecionadas na tela, permitindo que você:
- Adicione contexto às atividades.
- Relacione-as com outros atributos.
- Mapeie ou desfaça o mapeamento de atributos adicionais conforme necessário.
Ao fixar o mapa de processo do seu dataset na tela, você pode começar a enriquecer seu processo com atributos detalhados, relacionamentos e contexto, transformando dados brutos em insights práticos.
Atividades não mapeadas
Atividades não mapeadas são aquelas presentes no dataset, mas que ainda não foram vinculadas a nenhum atributo no modelo. Elas representam possíveis lacunas ou elementos que precisam ser integrados ao design do seu processo.
Ao ativar ou desativar a opção Atividades não mapeadas, os dados não mapeados serão representados visualmente com linhas pontilhadas. Isso facilita a identificação e a distinção dessas atividades em relação às já mapeadas.
No exemplo visual, você pode observar o estado antes e depois de alternar a opção de atividades não mapeadas:
- Antes: As atividades não mapeadas ficam ocultas e não aparecem na tela.
- Depois: As atividades não mapeadas surgem com linhas pontilhadas, destacando áreas que podem ser mapeadas.
Com este recurso, você pode gerenciar e tratar dados não mapeados com eficiência, garantindo que seu modelo de processo seja o mais completo e preciso possível.
Considerações finais
Mapear datasets no ProcessMind transforma seus dados em uma ferramenta poderosa de análise de processos. Não importa se você começa com um processo definido ou com dados brutos, a flexibilidade da plataforma garante que você possa construir e refinar seu modelo conforme necessário. Seguindo esses passos, você poderá criar um modelo completo com confiança, revelando insights valiosos para impulsionar a melhoria dos processos.