Datensets zuordnen in ProcessMind
Datensets in ProcessMind zuordnen
Das Mapping von Datensets ist wichtig, um RohDaten in konkrete Optimierungspotenziale in ProcessMind umzuwandeln. Ein großer Vorteil von ProcessMind ist die Flexibilität: Daten können jederzeit hinzugefügt, entfernt, aktiviert oder den Antrag bearbeitet.eaktiviert werden. Es gibt keine feste Reihenfolge oder zwingende Integration.
Sie haben zwei Hauptwege im Umgang mit Daten:
- Daten nach Prozessdefinition hinzufügen: Beginnen Sie mit einem Prozess-Framework und binden Sie Daten ein, um Lücken zu finden und Ihre Analyse zu verfeinern.
- Mit Daten starten: Verwenden Sie Ihre Event-Daten, um sofort eine erste Prozessablauf zu erstellen und darauf aufbauend weiterzuarbeiten.
Die Flexibilität ermöglicht, den für Sie passenden Ansatz zu wählen.
Für diese Dokumentation nehmen wir an, dass Sie mit einer leeren Arbeitsfläche starten und Ihren Prozess sowie die Analyse Schritt für Schritt aufbauen. Wenn Sie lieber mit einem bestehenden Prozess starten möchten, können Sie ein bereits vorhandenes BPMN-Modelll importieren und dann Daten direkt auf Aufgaben und Ereignisse des importierten Modells abbilden .
Schritt 1: Start mit leerem Canvas
Erstellen Sie einen neuen Prozess oder öffnen Sie einen bestehenden. Die Canvas bildet die Grundlage Ihres Modells, auf der Sie Datensets abbilden und organisieren. Falls Sie Ihre Daten noch nicht im Datenbereich hochgeladen haben, können Sie das auch direkt aus der Prozessansicht erledigen: Gehen Sie einfach ins rechte Panel und wählen Sie den Datenset-Modalbereich, wie unten abgebildet.
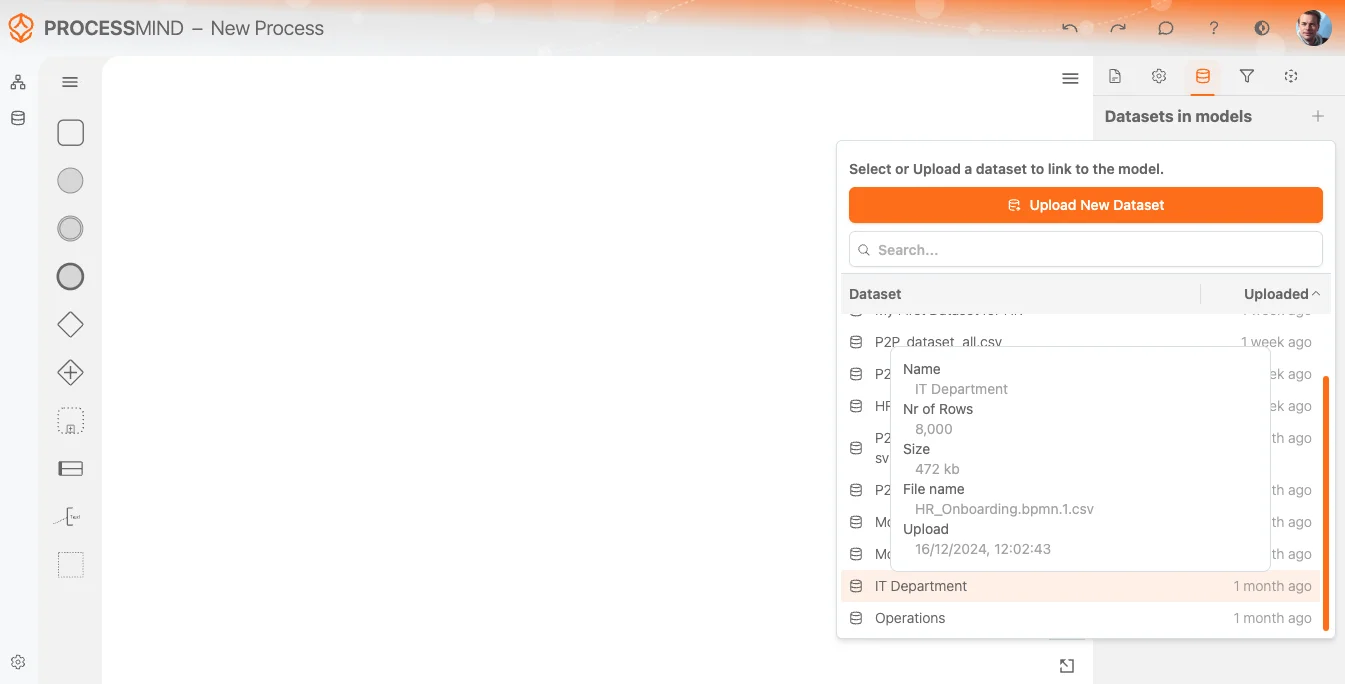
Datensatz auswählen
Sobald Ihr Datensatz hochgeladen und verarbeitet wurde, Hinweisrmiert Sie das System darüber, dass er bereit zur Nutzung ist. Anschließend können Sie ihn aus der Datenset Liste auswählen, wie oben im Bild gezeigt. Der zuletzt hochgeladene Datensatz steht immer ganz oben für schnellen Zugriff.
Wenn Sie mit der Maus über einen Datensatz in der Listee fahren, erscheint ein Tooltip mit weiteren Infos, etwa:
- Name des Datensatzes
- Anzahl der erkannten Zeilen
- Größe und Name der hochgeladenen Datei
- Hochlade-Datum und Uhrzeit
So stellen Sie sicher, dass Sie den richtigen Datensatz für Ihren Prozess auswählen.
Nach der Auswahl führt das System ein kurzes Pre-Processing durch. Dies wird durch ein Lade-Icon neben dem Datensatznamen angezeigt.
Im Kontext Ihres Prozesses können Sie den Datensatz (falls gewünscht) umbenennen, um ihn später leichter erkennen zu können. Mit dem Schalter wählen Sie, ob der Datensatz für die Prozesse aktiviert oder den Antrag bearbeitet.eaktiviert ist.
Datenset-Optionen
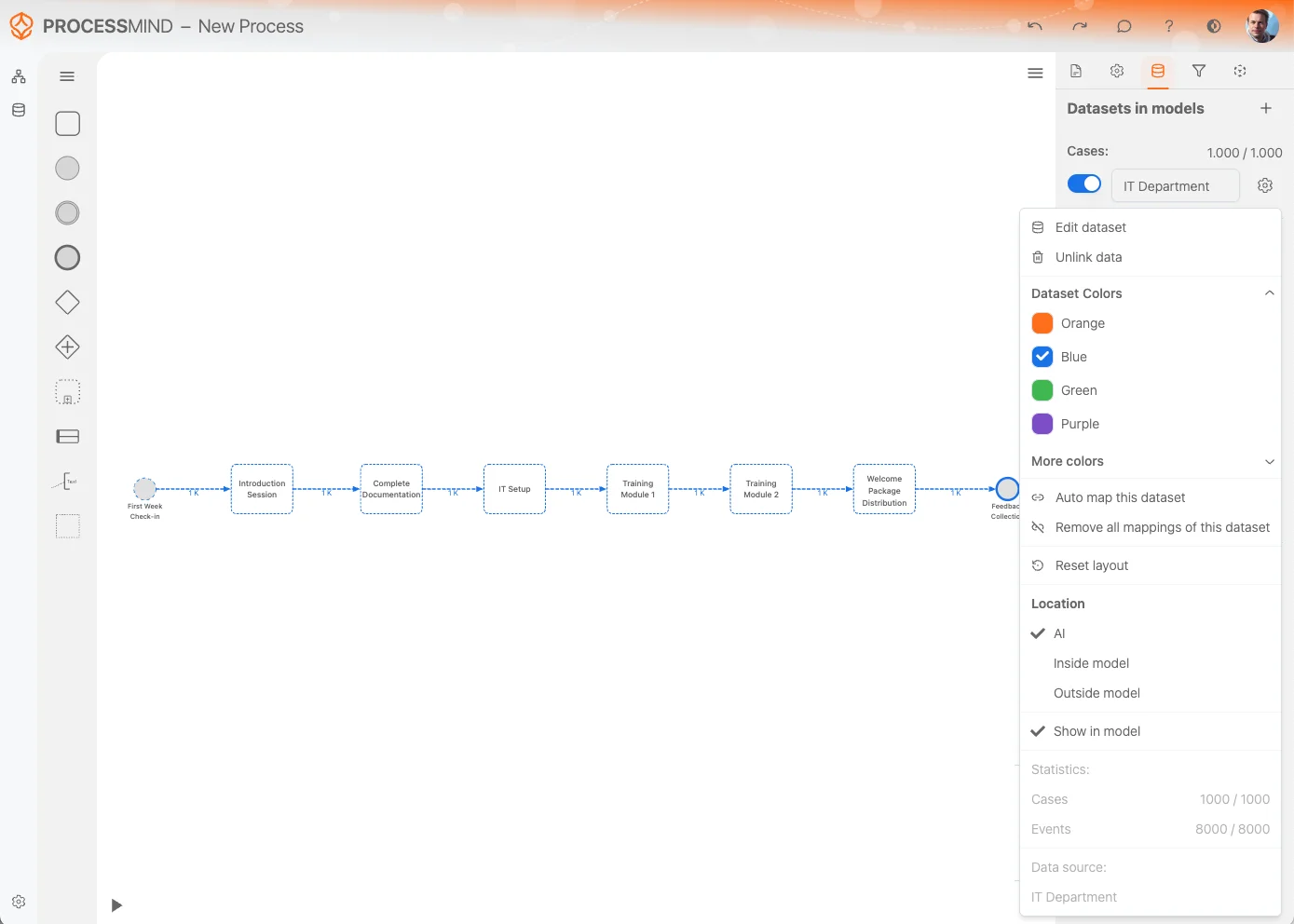
Das Datenset-Einstellungsmenü bietet verschiedene Möglichkeiten zur effektiven Verwaltung und Anpassung Ihrer Datensets. Hier die Optionen im Überblick:
-
Edit Datenset:
Über die Funktion Edit Datenset können Sie das Datenset direkt bearbeiten und anpassen. -
Unlink Daten:
Wird das Datenset im Prozess nicht mehr gebraucht, entfernen Sie alle Verknüpfungen mit Unlink Daten. Das Datenset verschwindet damit von der Canvas, bleibt aber in der Datenset Liste erhalten.
Hinweis: Das Datenset selbst wird nicht gelöscht. -
Datenset Colors:
Ändern Sie die Farbe des Datensets für bessere Unterscheidung. Die gewählte Farbe gilt auch für zugehörige Aktivitäten auf der Canvas. -
Auto Map Datenset:
Aktivitäten des Datensets werden automatisch auf bereits vorhandene Aktivitäten im Prozessmodell gemappt. Das spart Zeit und erhöht die Konsistenz. -
Remove All Zuordnungen:
Löscht alle Verknüpfungen zwischen Datenset und Prozessmodell: praktisch, wenn Sie neu starten oder viel ändern möchten. -
Reset Layout:
Mit Reset Layout werden Aktivitäten und deren Beziehungen auf der Canvas neu geordnet und übersichtlicher dargestellt. -
Location:
Bestimmen Sie, wo das automatisch generierte Modell erscheint:- AI (Smart Detection): Wählt den besten Platz automatisch.
- Inside Model: Modell erscheint innerhalb der Canvas.
- Outside Model: Modell wird außerhalb des Prozessdesigns angezeigt.
-
Show in Model:
Diese Option blendet Aktivitäten aus dem Datenset aus, die noch nicht direkt im Modell gemappt sind. Damit steuern Sie die Sichtbarkeit von nicht zugeordneten Aktivitäten. -
Statusstics:
Zeigt Statusstik zum Datenset, zum Beispiel:- Number of Fälle and Ereignisse: Schnelle Übersicht zur Datenset-Größe.
- Original Datenquelle Name: Datensatzquelle zur schnellen Referenz.
Mit diesen Optionen verwalten Sie Integration, Darstellung und Verhalten der Datensets in Ihren Prozessmodellen effizient und sorgen für einen klaren Workflow.
Daten dem Prozess zuordnen
Wenn das Datenset komplett geladen ist, zeigt das System automatisch das Process Mining-Ergebnis auf der Canvas. Diese anfängliche Prozessablauf ist ein freischwebendes Modell ohne feste Verankerungen. Um es in Ihr Prozessmodell zu übernehmen und bearbeiten zu können, ordnen Sie es einem bestehenden Modell oder einer Aktivität zu oder wandeln es in ein festes Modell um.
Modell auf der Canvas fixieren
Es gibt zwei Methoden, Aktivitäten vom schwebenden Modell auf der Canvas zu verankern:
-
Aktivitäten einzeln auswählen:
Wählen Sie gezielte Aktivitäten aus, um sie individuell zu abbilden. -
Mehrfachauswahl:
Mit dem Auswahlwerkzeug oder Shortcuts markieren Sie mehrere Aktivitäten gleichzeitig:- Shift + Maus ziehen: Auswahlbox um die Aktivitäten aufziehen.
- Alle auswählen: Mit
Ctrl + A(Windows) oderCommand + A(MacOS) alle Aktivitäten markieren.
Nach der Auswahl erscheint ein Kontextmenü neben den markierten Aktivitäten. Wählen Sie dort: Add to Model: So werden die Aktivitäten auf der Canvas fixiert, sodass Sie:
- Aktivitäten mit Kontext versehen.
- Weitere Attribute zuordnen.
- Attribute flexibel abbilden oder wieder lösen.
Durch das Fixieren der Prozessablauf des Datensets auf der Canvas reichern Sie Ihr Prozessmodell mit Details, Beziehungen und Kontext an. Daraus entstehen verwertbare Erkenntnisse.
Unmapped Aktivitäten
Unmapped Aktivitäten sind Aktivitäten, die im Datenset vorhanden sind, aber noch keinen Attributen im Modell zugeordnet wurden. Sie zeigen potenzielle Lücken oder noch zu integrierende Aspekte im Prozessdesign.
Bei Aktivierung der Option Unmapped Aktivitäten werden diese Aktivitäten mit gepunkteten Linien dargestellt. So erkennen und unterscheiden Sie sie einfach von bereits gemappten Aktivitäten.
Im Beispielbild sehen Sie den Zustand vorher und nachher beim Umschalten:
- Vorher: Unmapped Aktivitäten sind ausgeblendet und erscheinen nicht auf der Canvas.
- Nachher: Unmapped Aktivitäten sind mit gepunkteten Linien sichtbar und markieren Stellen fürs Mapping.
Mit dieser Funktion können Sie nicht zugeordnete Daten gezielt adressieren, um ein vollständiges und exaktes Prozessmodell.
Fazit
Das Mapping von Datensets in ProcessMind macht Ihre Daten zu einem kraftvollen Werkzeug für Prozessanalyse. Sie starten mit einem Prozessmodell oder RohDaten: die Plattform bleibt jederzeit flexibel, sodass Sie Ihr Modell beliebig anpassen können. Mit diesen Schritten erstellen Sie ein Modell, das relevante Einblicke liefert und die Prozessoptimierung unterstützt.