Cartographier les donnéessets
Cartographier les donnéessets dans ProcessMind
La cartographie des donnéessets est indispensablele pour transformer les données brutes en perspectives concrètes dans ProcessMind. L’une des grandes forces de ProcessMind, c’est sa flexibilité : vous pouvez ajouter, supprimer, activer ou désactiver les données à tout moment. Il n’y a pas d’ordre imposé ni de méthode contraignante pour intégrer des données à vos processus.
Vous pouvez aborder vos données de deux façons principales :
- Ajouter des données après avoir défini un process : commencez par une structure de process, puis intégrez des données pour identifier les informations manquantes et affiner votre analyse.
- Premiers pas par les données : utilisez vos données d’event pour créer une cartographie initiale, puis développez-la.
Cette flexibilité vous permet d’adopter l’approche la plus adaptée à vos besoins.
Dans ce guide, nous supposons que vous commencez sur un canvas vide et que vous construisez votre processus et votre analyse étape par étape. Si vous préférez utiliser un processus existant, vous pouvez importer un modèle BPMN existant puis mapper les données sur les tasks et events du modèle importé directement.
Étape 1 : Commencez avec un canvas vide
Créez un nouveau processus ou ouvrez-en un existant. Le canvas est la base de votre modèle, là où vous mappez et organisez vos donnéessets. Si vous n’avez pas importé vos données dans la section dédiée, vous pouvez aussi les uploader directement dans la vue process, via le panneau droit, en accédant à la section donnéesset du modal comme illustré ci-dessous.
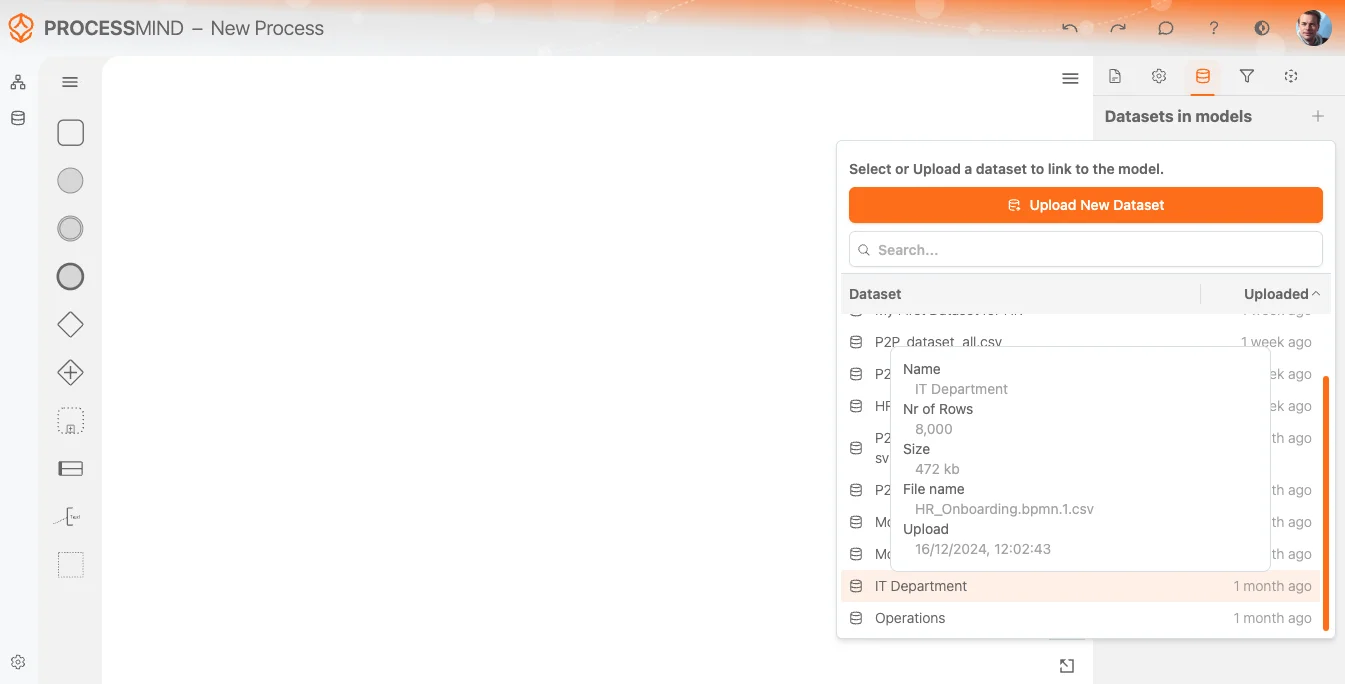
Sélectionnez votre jeu de données de données
Dès que votre jeu de données de données est importé et traité, le système vous informe qu’il est prêt à l’emploi. Vous pouvez alors le sélectionner dans la liste des donnéessets (voir l’exemple ci-dessus). Le dataset le plus récemment chargé s’affiche toujours en haut pour un accès rapide.
Quand vous survolez un dataset, une info-bulle donne des détails utiles :
- Nom du dataset
- Nombre de lignes identifiées
- Taille et nom du fichier
- Date et heure d’upload
Cela vous aide à choisir le bon dataset à mapper sur votre process.
Après la sélection, le système effectue un pré-traitement, signalé par une icône de chargement à côté du nom du dataset.
Pour clarifier son usage dans ce process, vous pouvez renommer le dataset si besoin, afin de le repérer plus facilement ensuite. Le switch vous permettra d’activer ou de désactiver le dataset pour les processus concernés.
Options du Dataset
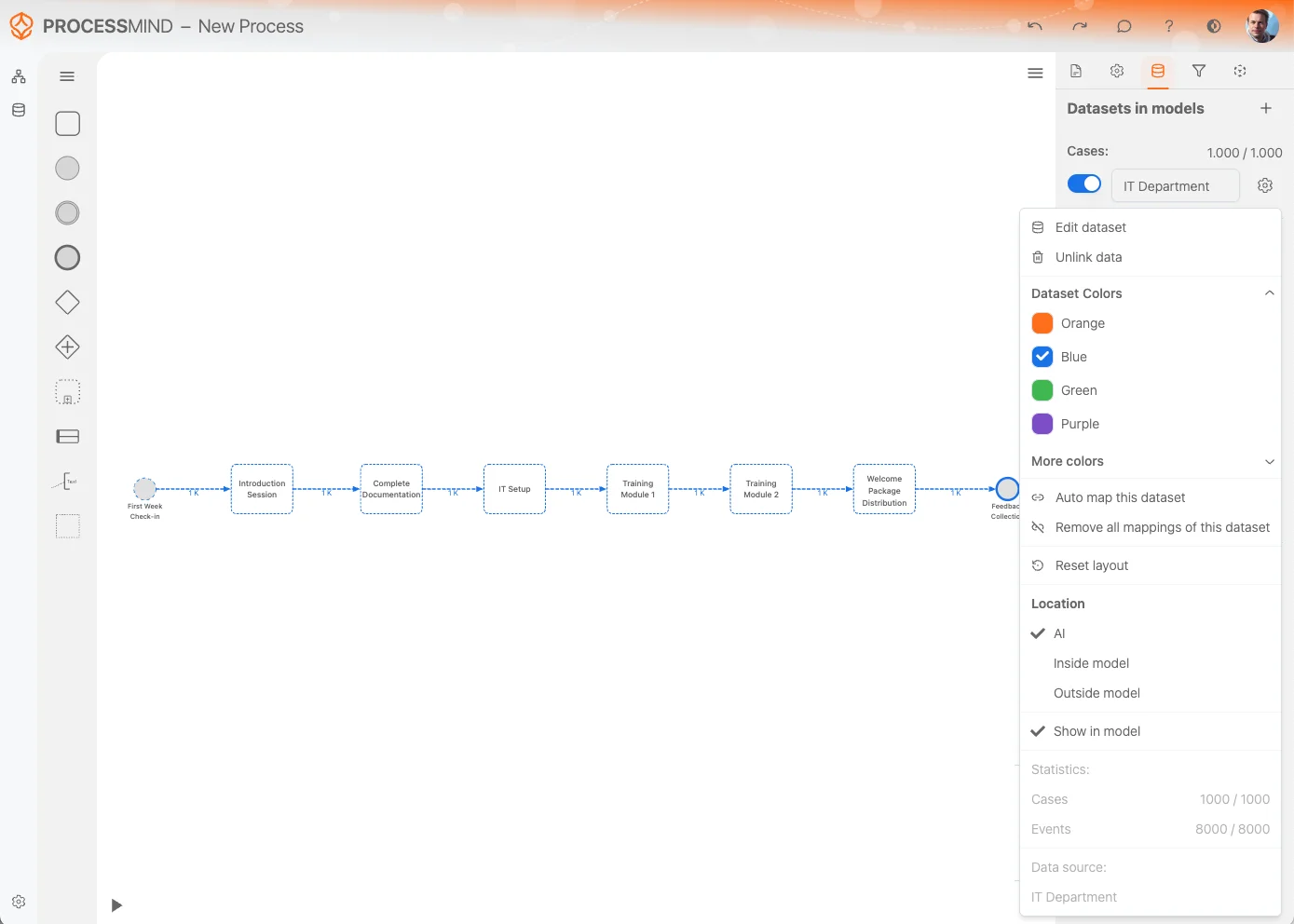
Le Menu des paramètres du Dataset propose plusieurs options pour gérer et personnaliser votre jeu de données de données de manière efficace. Voici le détail des options disponibles :
-
Modifier le dataset :
Accédez rapidement à l’option Edit Dataset pour modifier ou affiner le dataset directement. -
Délier les données :
Si le dataset ne vous est plus utile dans votre process, utilisez Unlink Data pour retirer toutes ses références et le retirer du canvas.
Remarque : Cette action ne supprime pas le dataset lui-même ; il reste disponible dans la liste des Datasets. -
Couleurs du Dataset :
Changez la couleur des donnéessets pour une meilleure distinction visuelle. La couleur choisie sera aussi appliquée aux activités issues de ce dataset, facilitant leur identification sur le canvas. -
Mappage automatique :
Cette option tente de mapper automatiquement les activités du dataset aux activités déjà présentes dans votre modèle de processus. Cela vous fait gagner du temps et aide à garder la cohérence. -
Supprimer tous les mappings :
Utilisez cette option pour effacer tous les mappings d’activités entre le dataset et votre modèle de processus. Pratique pour recommencer ou effectuer des changements importants. -
Réinitialiser la disposition :
L’option Reset Layout réorganise automatiquement les activités et leurs relations sur le canvas pour une meilleure clarté. -
Emplacement :
Déterminez où le modèle généré sera affiché.- AI (Smart Detection) : Décide automatiquement du placement optimal.
- Dans le modèle : Place le modèle dans le canvas du process.
- Hors du modèle : Affiche le modèle en dehors du design du process pour une meilleure séparation.
-
Afficher dans le modèle :
Cette option permet de masquer les activités du dataset qui ne sont pas directement associées dans le modèle. Activez-la pour gérer la visibilité des activités non associées. -
Statistiques :
Consultez les détails statistiques du dataset, notamment :- Nombre de cases et d’événements : Résumé rapide de la taille du dataset.
- Nom de la source de données d’origine : Affiche la source du dataset pour référence facile.
En utilisant ces options, vous gérez facilement l’intégration, la représentation et le comportement des donnéessets dans vos modèles de process pour un workflow fluide et organisé.
Mapper les données sur le process
Une fois votre jeu de données de données chargé, le système affiche automatiquement le résultat de Process Mining sur le canvas. Cette première MAP de process est un modèle flottant, non fixé. Pour l’ajouter à votre conception de processus et le rendre éditable, mappez-le sur un modèle ou une activité existants, ou convertissez-le en modèle fixé.
Fixer le modèle sur le canvas
Il existe deux méthodes pour fixer les activités du modèle flottant sur le canvas :
-
Sélectionner les activités individuellement :
Sélectionnez les activités à mapper une par une. -
Sélection multiple :
Utilisez l’outil de sélection ou les raccourcis clavier pour choisir plusieurs activités à la fois :- Shift + glisser la souris : sélectionnez plusieurs activités avec un cadre.
- Tout sélectionner : faites
Ctrl + A(Windows) ouCommand + A(MacOS) pour tout sélectionner.
Après sélection, un menu contextuel s’affiche près des activités. Choisissez Ajouter au modèle pour fixer les activités sélectionnées sur le canvas. Vous pourrez alors :
- Ajouter du contexte à ces activités,
- Les relier à d’autres attributs,
- Mapper ou retirer d’autres attributs selon vos besoins.
En fixant la MAP de votre jeu de données de données au canvas, vous enrichissez votre process grâce à des attributs détaillés, des relations et du contexte, et transformez vos données brutes en connaissances opérationnelles.
Activités non associées
Les activités non associées sont présentes dans le dataset mais pas encore rattachées à des attributs du modèle. Elles signalent des points à intégrer pour compléter votre Conception de processus.
En activant l’option Unmapped Activités (Activities), ces activités seront affichées avec des lignes pointillées pour les distinguer facilement des activités déjà associées.
L’exemple ci-dessous montre l’état avant et après le basculement de l’option :
- Avant : les activités non associées sont cachées sur le canvas.
- Après : elles sont visibles avec des lignes pointillées, pour montrer ce qui reste à mapper.
Grâce à cette fonctionnalité, vous pouvez rapidement pointer et traiter les données non associées, afin d’obtenir un modèle de processus complet et fiable.
Conclusion
La cartographie de vos donnéessets dans ProcessMind transforme vos données en un outil puissant d’analyse des processus. Que vous commenciez par un process défini ou par des données brutes, la flexibilité de la plateforme vous permet de construire et d’ajuster votre modèle à tout moment. En suivant ces étapes, vous créez un modèle complet qui révèle des insights concrètes et favorise l’amélioration des processus.