Mapeo de datasets en ProcessMind
Mapeo de datasets en ProcessMind
Mapear datasets es un paso clave para convertir data bruta en insights accionables dentro de ProcessMind. Una de las principales ventajas de ProcessMind es su flexibilidad: puedes agregar, quitar, habilitar o deshabilitar data en cualquier momento. No hay un orden fijo ni una manera obligatoria de integrar la data a tu proceso.
Puedes trabajar con la data de dos formas principales:
- Agregar data después de definir el proceso: Comienza con un esquema del proceso y agrega la data para identificar información faltante y mejorar tu análisis.
- Empezar desde la data: Usa tu event data para crear un primer mapa de procesos y desarrolla tu modelo desde ahí.
Esta flexibilidad te permite elegir el enfoque que mejor se adapte a tus necesidades.
Para los fines de esta documentación, asumimos que comienzas con un canvas vacío y vas construyendo tu proceso y análisis paso a paso. Si prefieres empezar con un proceso existente, puedes importar un modelo BPMN existente y mapear data a las tasks y events del modelo importado directamente.
Paso 1: Comienza con un canvas vacío
Crea un proceso nuevo o abre uno existente. El canvas es la base de tu modelo, donde vas a mapear y organizar los datasets. Si aún no subiste tus datos en la sección de data, también puedes subirlos directamente desde la vista de proceso. Hazlo desde el panel derecho y selecciona el dataset en la sección modal, como se muestra en la imagen abajo.
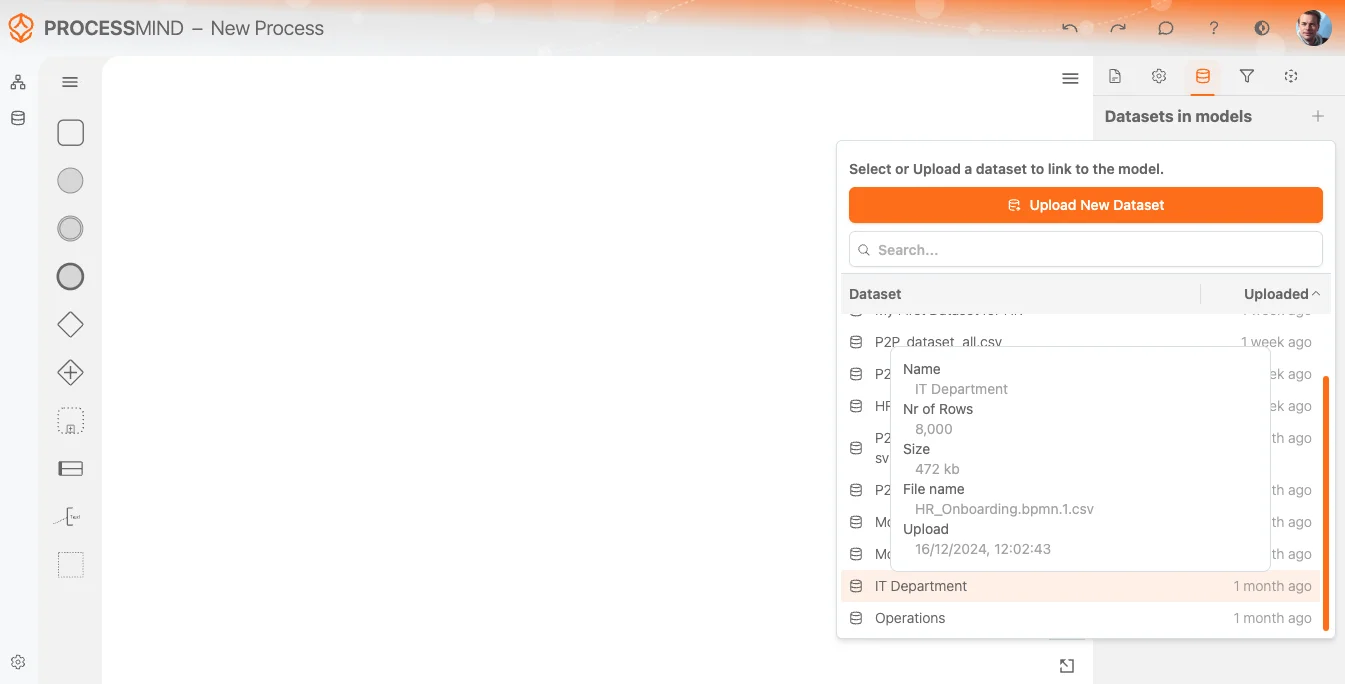
Selecciona tu dataset
Una vez que tu dataset esté subido y procesado, el sistema te notificará que está listo para usarse. Puedes seleccionarlo en la Lista de datasets, como se muestra en la imagen de arriba. El dataset más reciente aparecerá siempre en primer lugar para facilitar el acceso.
Al pasar el cursor sobre un dataset, verás un tooltip con información adicional como:
- Nombre del dataset
- Número de filas identificadas
- Tamaño y nombre del archivo subido
- Fecha y hora de subida
Esto ayuda a asegurar que seleccionas el dataset correcto para tu proceso.
Después de seleccionar tu dataset, el sistema realizará un pre-procesamiento básico, marcado por un ícono de carga junto al nombre.
Para mayor claridad, puedes renombrar el dataset (si quieres) para este proceso, lo que facilita identificarlo más adelante. La opción de switch te permite habilitar o deshabilitar el dataset para tus procesos.
Opciones de dataset
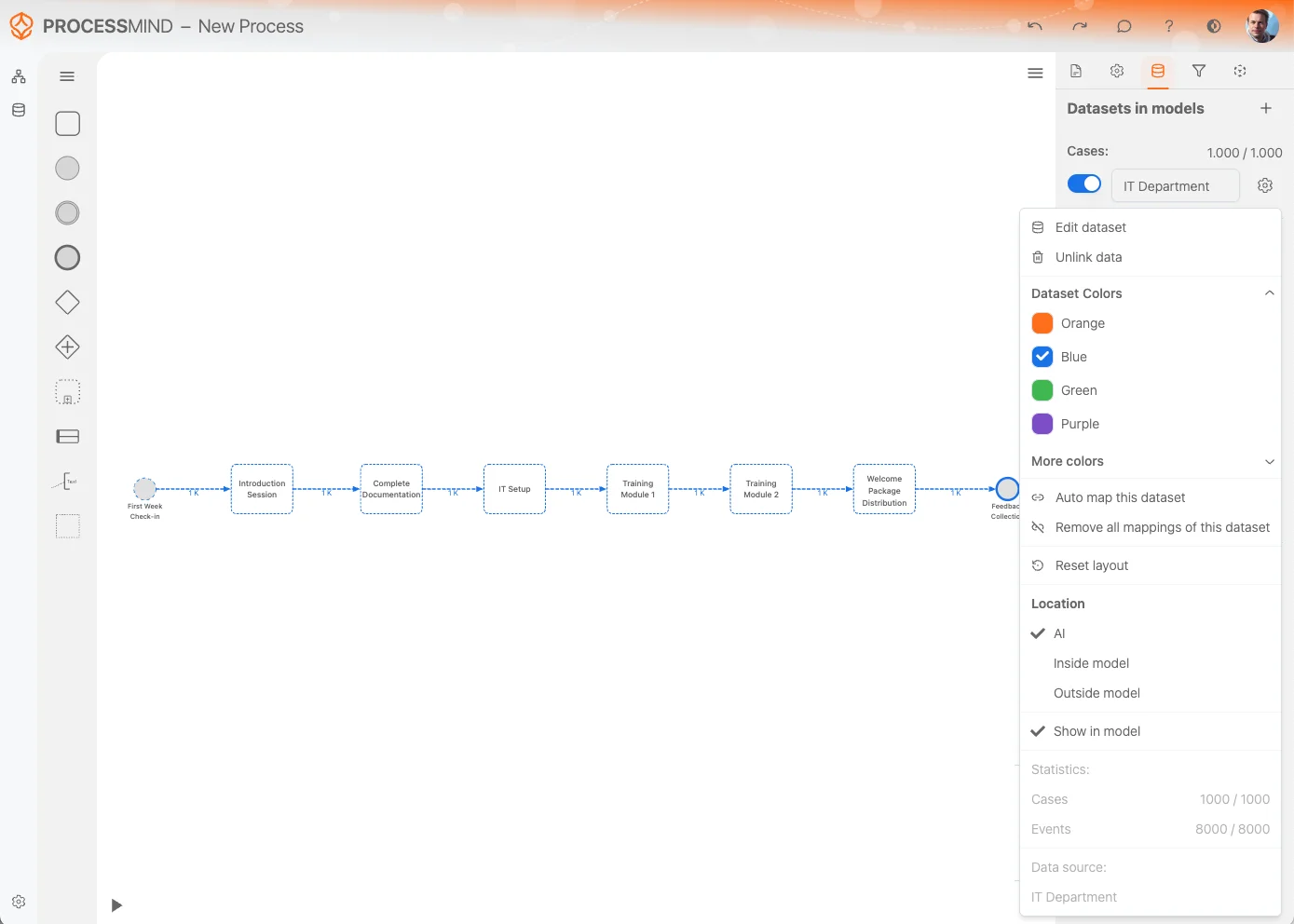
El Menú de configuración del dataset ofrece varias opciones para gestionar y personalizar tu dataset de forma eficiente. Aquí tienes un resumen de las opciones disponibles:
-
Editar dataset:
Accede rápido a la opción Editar dataset para modificar o ajustar tu dataset directamente. -
Desvincular data:
Si ya no necesitas el dataset en tu proceso, usa la opción Desvincular data. Esta elimina todas las referencias al dataset y lo quita del canvas del proceso.
Nota: Esta acción no borra el dataset; sigue disponible en la lista de datasets. -
Colores del dataset:
Cambia el color del dataset para distinguirlo visualmente. El color seleccionado también se aplicará a actividades derivadas de este dataset, facilitando su identificación en el canvas. -
Auto Map Dataset:
Esta opción intenta mapear automáticamente las actividades del dataset con las actividades ya representadas en tu modelo de proceso, ahorrando tiempo y manteniendo la consistencia. -
Eliminar todos los mappings:
Utiliza esta opción para borrar todos los mappings entre el dataset y tu modelo de procesos. Útil si necesitas empezar de cero o hacer cambios importantes. -
Restablecer layout:
La opción Restablecer layout organiza automáticamente las actividades y sus relaciones en el canvas para mayor claridad. -
Ubicación:
Decide dónde se mostrará el modelo generado automáticamente:- AI (Smart Detection): Decide la ubicación óptima automáticamente.
- Inside Model: Coloca el modelo dentro del canvas del proceso.
- Outside Model: Muestra el modelo fuera del diseño del proceso para separarlo visualmente.
-
Mostrar en el modelo:
Permite ocultar actividades encontradas en el dataset que no están mapeadas directamente en el modelo. Activa o desactiva para gestionar la visibilidad de las unmapped activities. -
Estadísticas:
Consulta detalles estadísticos del dataset, como:- Número de cases y events: Resumen rápido del tamaño del dataset.
- Nombre original de la fuente de datos: Muestra la fuente de origen para referencia práctica.
Aprovechando estas opciones, puedes gestionar la integración, presentación y comportamiento de tus datasets en tus modelos de procesos, logrando un workflow organizado.
Mapear data al proceso
Una vez que el dataset se haya cargado por completo, el sistema mostrará automáticamente el resultado de Process Mining en el canvas. Este primer mapa de proceso es un modelo flotante, sin enlaces fijos. Para integrarlo en el diseño de tu proceso y editarlo, debes mapearlo a un modelo o actividad existente, o convertirlo en un modelo fijo.
Fijar el modelo al canvas
Hay dos formas principales de fijar actividades del modelo flotante al canvas:
-
Seleccionar actividades individualmente:
Elige las actividades específicas para mapear una por una. -
Selección múltiple:
Usa la herramienta de selección o atajos de teclado para elegir varias actividades a la vez:- Shift + arrastrar con el mouse: Dibuja un cuadro de selección alrededor de las actividades.
- Seleccionar todo: Presiona
Ctrl + A(Windows) oCommand + A(MacOS) para seleccionar todas las actividades.
Tras tu selección, aparecerá un menú contextual junto a las actividades. Ahí puedes elegir: Agregar al modelo: Esta opción fija las actividades al canvas y te permite:
- Añadir contexto a las actividades.
- Relacionarlas con otros atributos.
- Mapear o desmapear atributos adicionales según sea necesario.
Al fijar el mapa de procesos de tus datasets en el canvas, enriqueces tu proceso con atributos detallados, relaciones y contexto, convirtiendo la data en insights accionables.
Actividades sin mapear
Las unmapped activities son actividades presentes en el dataset que aún no se han mapeado a atributos del modelo. Representan posibles huecos o elementos a integrar en tu diseño de proceso.
Al activar o desactivar la opción Unmapped Activities, estas aparecerán con líneas punteadas para identificarlas y diferenciarlas de las actividades mapeadas.
En el ejemplo visual se observa el antes y el después de activar la opción de unmapped activities:
- Antes: Las unmapped activities están ocultas y no se ven en el canvas.
- Después: Las unmapped activities aparecen con líneas punteadas, destacando áreas para mapear.
Usar esta función te permite gestionar y revisar rápidamente la data sin mapear, asegurando que tu modelo de procesos esté lo más completo y preciso posible.
Reflexiones finales
El mapeo de datasets en ProcessMind convierte tus datos en una herramienta potente para el análisis de procesos. Tanto si partes de un proceso definido como de datos brutos, la flexibilidad de la plataforma te permite construir y mejorar tu modelo según lo necesites. Siguiendo estos pasos, podrás crear un modelo completo que aporta insights accionables y fomenta la mejora continua de procesos.