Where to Source and Structure Data for Process Mining
Learn how to extract and structure data from business systems for process mining. Get best practices for preparing your data for analysis.
Under the Attributes tab, the screen displays the following columns for mapping and configuring the attributes from the uploaded dataset:
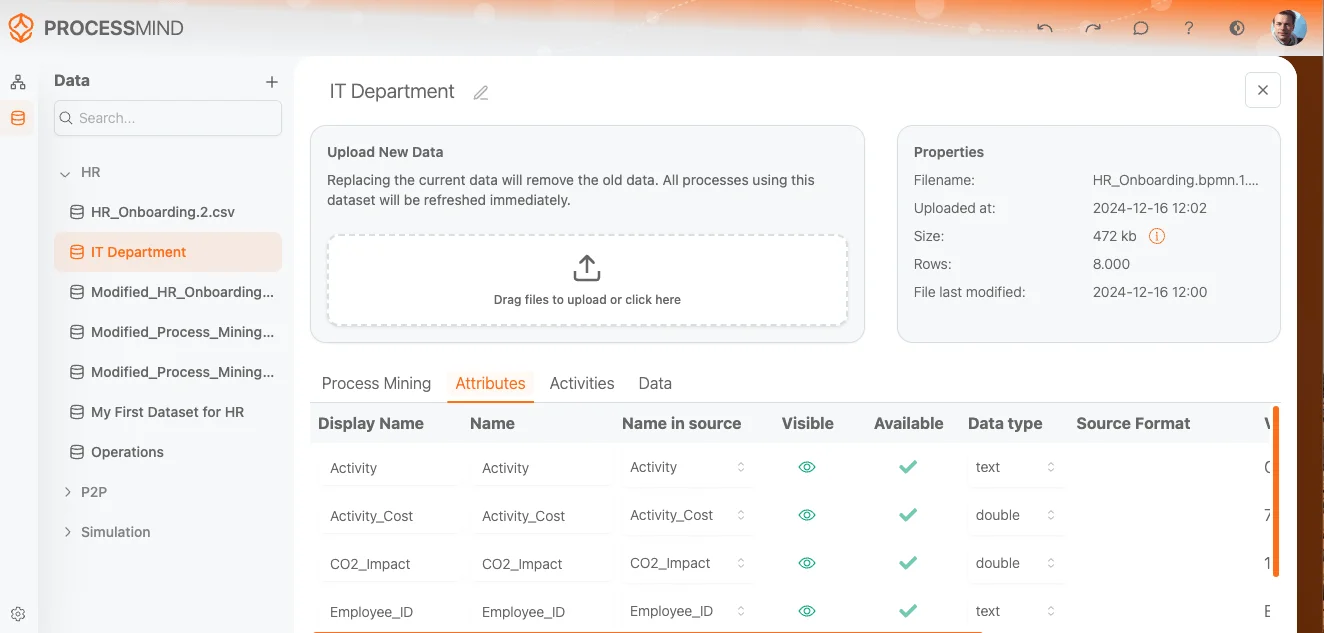
Indicates how each attribute will be labeled in the process mining section of the tool (e.g., “ACTIVITY”, “Case ID”, “EVENTTIME”).
The internal name for each attribute in the dataset. These names correspond to the columns in the dataset.
Shows the original column names from the uploaded dataset (in this case, “ACTIVITY”, “Case ID”, “EVENTTIME”). It’s possible to switch names in the source to other columns of the source dataset.
Green check marks indicate that the attribute is visible and will be used in the analysis. You can toggle visibility on or off as needed.
Green check marks indicate that the dataset contains valid data for the respective attribute.
Specifies the type of data in each column. Every type is validated to ensure data integrity and is auto-detected but can be changed if required. The following data types are available:
For Timestamps, ProcessMind supports the most common formats that will be automatically be detected on data upload. However, they can be changed if required.
Displays a preview of the actual data in the dataset for each attribute:
We use cookies to enhance your browsing experience, serve personalized content, and analyze our traffic. By clicking "Accept All", you consent to our use of cookies.